



AI to help green asset management: Monitoring urban trees
Nowadays, there is no IT news without mentioning AI related technologies. As IT has become central part of our entire economy, AI follows a similar trend and is going to be used where digital data are generated. That is, everywhere. Every process of business – be it manufacturing, marketing, HR, finance or logistics- is being transformed by AI. How do we know if AI is not just another hype and that data driven thinking will stay? AI is not a pet project in a university lab, technology is getting mature, new discoveries get into production at an unprecendented pace. With the proper use of AI technology complex systems become more transparent and explainable, control or at least forecast becomes easier.
To make it all happen, we need new perspectives, new organizational models, new IT solutions.
However, while many applications of next-gen AI technology are truly amazing, the role of AI in most use cases are less articulated or hard to explain.
As we understand business logic, we can help identify, analyze and create optimal solutions for our business partners via clean and transparent methods. Magic is in human creativity and not in “AI black boxes” anymore. In this blog we are excited to showcase one particular application where AI has a significant impact on the life quality of an entire population.
The task: green asset management in Singapore
 |
| Forrás: https://cutt.ly/vkW439J |
Singapore –or the Garden City– has earned the badge of the greenest city on Earth having about 1-2 million planted trees. However, the maintenance of the complex system of the various parks, forests and streets requires an enormous amount of manpower, resources and skills. Climate change makes the task even more difficult as local weather conditions have significantly changed in the last few years, shortening life expectancy of the trees and helping the spread of various diseases (funghi, bacteria, insects). Since the life quality of the citizens depends a lot on the well being of the vegetation, proper responses must be taken to preserve and improve the green areas.
What is needed then? NParks – responsible for all public green areas within Singapore- put together an action plan (https://cutt.ly/zkKamWm ). First, an automated monitoring system was developed that not only helps to assess the present state of the environment, but also it is the foundation of environmental modeling that is used to direct future plantations and support risk analysis (like identifying trees that will likely fall). As a second step they need a computer aided system that can automate some parts of the data analysis so man power can better be utilized. Finally they will need a system that can create and fine tune weather and environmental models that can take into account all kinds of data to be collected in the future regarding the physical conditions of the city.
Automation in the data collection process is already a huge step, as one expert can only examine a few dozen trees per day during field work. Data collection now takes place as cars cruise the city and collect high-resolution LIDAR (Light Detection And Ranging) and panoramic images that capture the surroundings of the car.
Image s taken at various angles on the same object can be used to identify the relevant objects and pin their 3D position. The corresponding LIDAR 3D point cloud can then be used to reconstruct the detailed 3D morphology of the identified tree: tree height, diameter and angle of the tree trunk, position of the first branch bifurcation, volume of the green canopy, etc.
s taken at various angles on the same object can be used to identify the relevant objects and pin their 3D position. The corresponding LIDAR 3D point cloud can then be used to reconstruct the detailed 3D morphology of the identified tree: tree height, diameter and angle of the tree trunk, position of the first branch bifurcation, volume of the green canopy, etc.
Source: https://cutt.ly/0kW4OMU
In the beginning there was an attempt to manually reconstruct the trees from the 3D data points using those methods that surveyors still use. However, this approach was painstakingly slow and imprecise.
 |
| Ideally, the 3D point cloud obtained via LIDAR measurements can be segmented into meaningful parts like canopy, branches and trunk. Fine grained modeling of these parts can help estimate the entire morphology of the tree. Source: https://cutt.ly/AkW4VeT |
{kind=link}
Just thinking about the sheer amount of data makes one dizzy. That is why data processing must be automated as well. And here comes the challenge! How can we transfer the experts’ domain knowledge into something that a computer can use?
The low reliability of the aforementioned traditional approach stems from the fact that the entire approach was built on a set of complex and rigid rules. So our main task was to come up with a solution that can handle highly complex examples and can localize the trees and provide a geometrical model of each tree from which all the required parameters can be efficiently (fast and precisely) derived.
Solution in theory
We can see the widespread use of 3D models in various fields from infrastructure maintenance to healthcare (Engineering is basically all about 3D modeling nowadays.) Doctors can actively use 3D models previously created from imaging data during surgery, for example. Or think about self-driving cars. When moving, the system must quickly recognize all relevant static and moving objects. 2D images, however, are often hard to interpret or are too noisy to be helpful (low visibility, clutter, etc). On top of the physical limitations of the sensors, the amazing variety of the objects make the task even harder. That is why that rule based solutions just fail. So here comes Artificial Intelligence (well,actually it is better called Machine Learning (ML)) to our rescue! ML is an umbrella term for various methods that work quite well in real life scenarios.
The key aspect of these various methods is that they can extract and learn patterns or relationships between data (observations) and their annotations (tags given by human experts).
Learning is about tuning parameters of an algorithm so it becomes better at assigning tags to data. In our case, data are 3d points, annotations are labels like ‘tree trunk’ or ‘canopy’. By assigning a tag to each individual point, we actually do semantic segmentation: points are binned into meaningful groups or clusters.. When similar objects need to be detected and separated, then an additional label is used as an ID: points labeled with the same ID belong to the same object. This task is usually referred to as instance segmentation.
Solution in practice
Data, data, data
There are quite a few 3D point cloud annotated datasets available, most have different shortcomings that make them useless for our project. Some do not have information about trees, or their resolution is too low or the applied categories are just not fine enough. As an example, ‘high vegetation’ and ‘low vegetation’ labels are used in https://www.semantic3d.net/.
For this reason, our very first step was to help our partners create a large and heterogeneous training dataset from their own measurements. As several sensors are used, the dataset contains 3D point clouds and corresponding 2D images. Since the point clouds are not structured (as opposed to 2D images where each data point is linked to a grid), the resolution is high, the data are noisy and the objects are very complex, an ideal dataset would consists of a few thousand annotated point cloud (“3D volume”) and annotated (segmented) images. In reality you cook with what you have. All the results presented below were gained using only a few hundred volumes only!
Model selection and training
At the time we started working on this project, there were only a few efficient models available that could infer 3D object morphology from unstructured 3D point clouds.  We ruled out some as they required way too many data or seemed to be too slow to be of practical use. There was an important lesson. While there are many more images and the 2D segmentation algorithms are quite mature, the analysis of 3D models is actually faster as 3D data is more sparse. So instead of following a complicated approach where we directly integrate 2D and 3D data, we have built and tuned separate models for 2D and 3D segmentation. The final solutions included 2 steps. First, we trained a model to locate the trees (the center of the tree trunks on the ground). Second, we trained a combined model of two previously published solutions to segment the individual trees as well as their parts.
We ruled out some as they required way too many data or seemed to be too slow to be of practical use. There was an important lesson. While there are many more images and the 2D segmentation algorithms are quite mature, the analysis of 3D models is actually faster as 3D data is more sparse. So instead of following a complicated approach where we directly integrate 2D and 3D data, we have built and tuned separate models for 2D and 3D segmentation. The final solutions included 2 steps. First, we trained a model to locate the trees (the center of the tree trunks on the ground). Second, we trained a combined model of two previously published solutions to segment the individual trees as well as their parts.
An example for the output of our solution fine tuned on tree data:
  |
| 3D semantic segmentation. On the left we see the original view as captured by a 2D image. On the right we can see that the model separete the electric pylons from the canopy and large branches. The colors (“mask”) come from the 3D segmented data so the coordinates of each point can be mapped onto the 2D representation. |
Evaluation
The performance of the trained models was measured as accuracy on a portion of the annotated dataset that was never used during training. This process imiates how the model would work on future data thus making the evaluation more objective. The predicted labels were compared to the human annotations. The accuracy of the tree detection and the segmentation of the tree parts was the following:
| MIOU | Background | Canopy | Trunk-branches |
| 2D | 97% | 90% | 70% |
| 3D | 99% | 96% | 78% |
The metric is the so called mIOU (mean intersection over union), which is the normalized intersection of the real and predicted areas/volumes.
The next image is a visualization of the reference (human annotation) and the computer annotation of the same data:
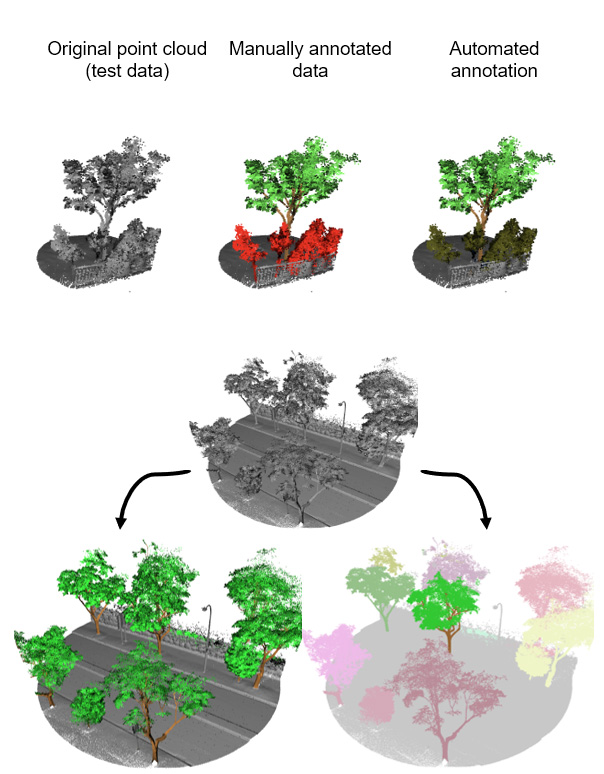 |
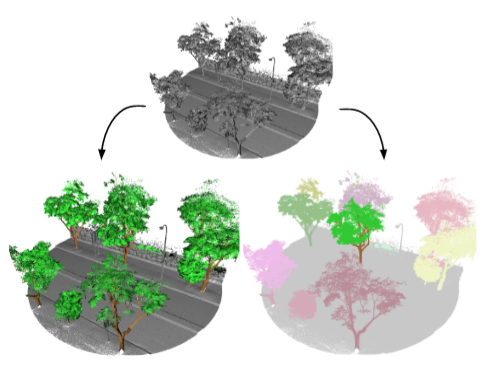
| The trained models can segment the tree parts (A) and the individual trees (B) |
Turning the solution into production
In this cooperation our main contribution was about creating the core of the ML solution. However, the work did not stop there. We have adviced our partner about the ideal software and hardware infrastructure and provided further support for integration our solution to the existing environment of NParks.
The final solution was created in a private cloud. The preprocessing of the incoming sensory data, model inference and logging and storage of the results take place in an efficient, distributed manner, where each step can be visualized and manually corrected if necessary. The models can be further improved by exploiting what we learn from those difficult cases where human correction are needed. For that, there is a dedidated loop-back system that collects the flagged cases and initiates a new learning process.
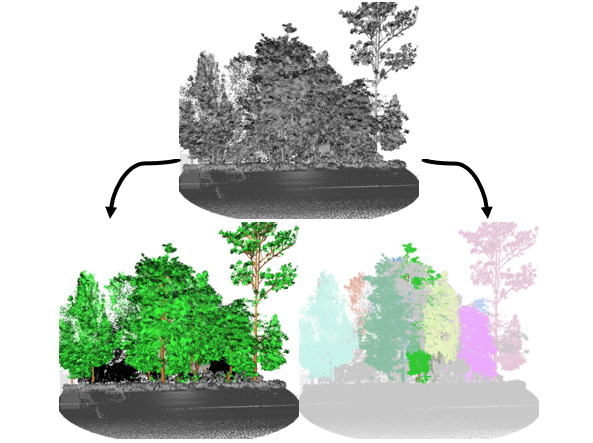 |
| The model works even for heavily cluttered tree groups, albeit with lower accuracy. Here it is also true that an ML solution is as good as the training set is. In this particular case annotation proved very difficult even for the human annotators. |
How can we help?
During the project we have met quite a few challenges typical to other practical tasks: “translating” the task into the language of algorithms, analysis and improvement of already eisting solutions, creation of proper data for training, etc. Hopefully this blog has given a useful and entertaing peek into the world of applied AI in business and industry.
If yo have a complex problem that you think could be solved by our AI stack, then let us have a talk!