



Do not let Big Bro in! – Security and privacy in elderly care
In our previous post we talked about how elderly care is becoming one of the most fundamental challenges across the world. It is clear that we will need all the tricks IT can offer, be it cloud computing, edge devices or AI. However, these shiny, new technologies are not without serious risks regarding privacy, material loss or even immediate danger of life. As elderly care regards, these risks are even more pronounced.
Picture this. You think your grandma is fine as her well-being is monitored indoor (using cameras, lidars, etc) and outdoor (via wearable devices, etc). But what if someone can tap into the data communication and can see when the apartment is empty. Or by stealing the biometric data, it is a piece of cake to steal money or commit fraud. What is even worse, what if someone can fiddle with the smart pacemaker or the insulin pump remotely? Well, actually, it did already happen (shorturl.at/bkrX2).
While all these hybrid (physical and cyber security) issues would worth a separate post on their own, we now want to introduce you to another aspect of privacy concerns: learning from highly sensitive data.
As we have talked about how data is important for learning complex patterns of the world, it is no surprise that health care monitoring or modeling behavioural patterns need lots of patient data. Those data can be as simple as the number of doctor-patient contacts a month or as complex as heart rate variation on a second by second basis. The problem is that we need to make sure that no personal information (“meta data”) gets mingled with the data needed to train the AI models. Why is that? Well, making such sensitive data open can pose direct threat to the participants. What is more, there is an indirect risk that can hurt even those who are not providing data to the training process, but are somewhat related to the patients.
For health monitoring, the problem is not limited to the model training phase. Continuous monitoring of the participants requires to maintain contact and repeated access to sensitive data. This data is then used to provide predictions as well as useful information to update (fine tune) the learning models (continual learning scenario). So how can we secure the flow of sensitive data? And how can we make sure that personal information is not getting into the wrong hands?
There are existing solutions that either try to hide or erase sensitive information (various kinds of anonymization) or try to deeply encrypt the communication channel.
However, there is another smart idea that is designed to render the communication of sensitive info unnecessary. This approach is called federated learning. Let us see what this is all about.
Federated Learning (FL)
According to WIKI: “Federated learning is a machine learning technique that trains an algorithm across multiple decentralized edge devices or servers holding local data samples, without exchanging them. Federated learning enables multiple actors to build a common, robust machine learning model without sharing data, thus allowing to address critical issues such as data privacy, data security, data access rights and access to heterogeneous data. Its applications are spread over a number of industries including defense, telecommunications, IoT, and pharmaceutics.”
The term was coined by Google (https://arxiv.org/abs/1602.05629v3) back at 2017.
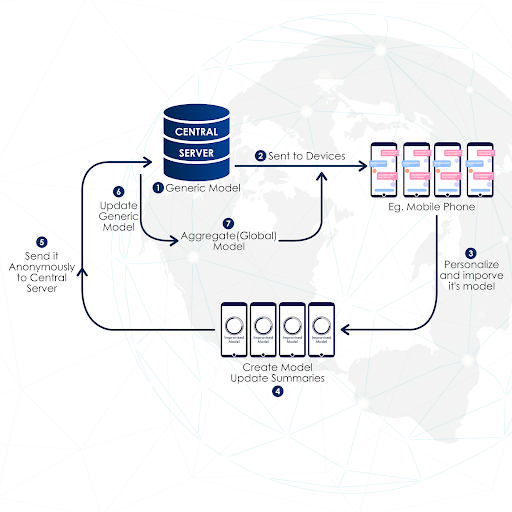 |
Let us dive into this complex definition. The first interesting technology involved is called distributed learning. To brush up our knowledge, let us talk a bit about machine learning, in particular, supervised learning. Here the task is to learn to associate labels with data. Machine learning algorithms learn the association by incrementally tuning parameters that define the chain of transformations that make up the algorithm. Now we talk about millions or billions of those parameters! That explains why training is so tedious in most cases. However, if several machines can parallel work on different bunch of data, then training becomes much faster if the trained model variations are properly combined into one single solution. The other thing that pops up is that FL is ideal when privacy preserving is of central importance. The whole idea is about minimizing data exchange between the clients (unit that can train a model on local data) and the server (a unit that aggregates local model updates, organizes parameter exchange, but does not have access to data). This particular issue is getting so important that it makes FL a central part of all AI applications across various indsutries and business: Google, IBM, Intel, Baidu or Nvidia have all come up with their enterprise grade FL frameworks (shorturl.at/dgiy7)!
The original idea was based on the assumption that edge devices (like smart phones) can both collect and process data locally. In turn, if models can fit into the phone’s memory, than it is enough to exchange local updates with a central model. This concept is called cross-device FL. Personalized texting like Gboard is using this approach.
Well, texting is fine on mobiles, but measuring blood sugar? So there is another real-life scenario. You already have shared your medical data with your doctor so as have all her other patients. In turn, the health care center can tune its own model using all the available data. Centers can exchange the model parameters without exposing their own patient data. This approach is called cross-silo FL.
See the picture below! Normally data are collected and aggregated across the different locations and a central unit trains a model using all the data collected. This setup definitely raises the red flag as sensitive medical records are moving around. But here comes cross-silo FL to the rescue! Privacy is preserved, well done!
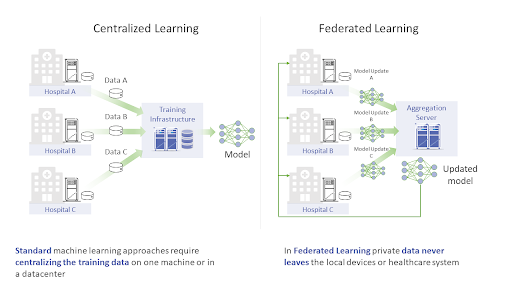 |
|
Source: https://openfl.readthedocs.io/en/latest/overview.html |
Clearly, cross-device and cross-silo FL types define the scaling dimension of FL. In the last few years many new ideas have been discussed and now there are at least 6 factors that are needed to differentiate between the various solutions.
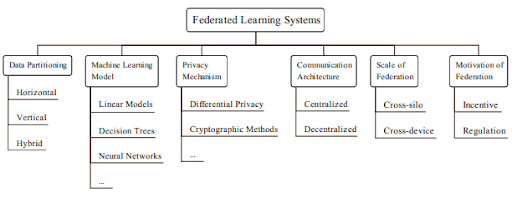 |
Data partitioning is about how participant and their features (data records) are treated across the different local models. While the original idea assumed that each client node has the very same representation on the participants, there are reak life scenarios where data gets partitioned by feature sets and not by user id. As an example, a bank and an insurance company may have access to different data on the very same user, yet they can mutually improve each other’s models.
Machine Learning modeling is about the core model applied within FL. The more complex the model, the more update exchange is needed. As FL regards, the most important question is how to aggregate the local updates when facing reliability and communication bandwidth issues.
Privacy Mechanism is a core component of the FL frameworks. The basic idea is to avoid information leakage amongst clients. Differential privacy (that is to separate user specific and generally relevant information) and cryptography are two frequently used approaches, but this is a constantly evolving field.
Communication Architecture. The original idea suggested an orchestrated approach to model training where the central server holds the aggregated model that is mirrored in the local units. More recent solutions drop centrality and suggest various decentralized updating mechanisms. In these solutions client nodes communicate with a few peers and there is a particular policy on update propagation.
We talked about Scaling, and the last point is about the Motivating Factors for applying FL. In some cases, stringent regulations force us to turn to FL (consider GDPR in Europe, CCPA in the US or PIPL in China). In other cases shared cost and increased reliability could be the main driving forces.
If you wonder why we have so many factors to check just think about the immensely different challenges in e-commerce (personalized ad), finance (fraud detection) or healthcare (remote diagnostics, etc, see https://www.nature.com/articles/s41746-020-00323-1). Different requirements require different solutions.
So what are the main challenges that FL solutions meet?
Communication efficiency
Updating large models requires sending large messages. Another problem is limited bandwidth: when a large number of clients try to send data, many will fail. The solution for the first problem involves a form of compression, while the second one is addressed by the introduction of decentralized (peer2peer and gossip) networks, when updates are exchanged locally. One example solution is depicted in the figure next:
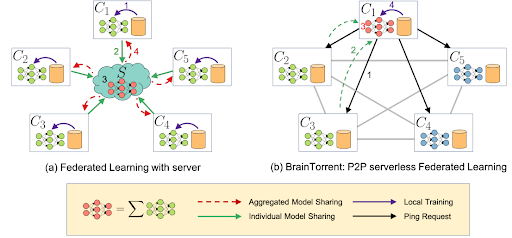 |
Privacy and data protection
While raw data stay where it was generated, model updates can be attacked and reveal private information. Some solutions are built around differential privacy, where only statistical (general) data are extracted and used for model training (https://privacytools.seas.harvard.edu/differential-privacy). Another interesting idea is to perform computation on encrypted data only (“homomorphic encryption” for those who like scientific terms). Yet another idea goes to the opposite direction: let us spread the sensitive data across many data owners, but computations can only be done in a collaborative fashion. Cool, isn’t it?
Diverse hardware
For really large FL systems, nodes are most likely quite different in terms of storage capacity, computing power, and communication bandwidth. And only a handful of them participates in the update at a given time, resulting in biased training. Solution? Asynchronous communication, sampling of active devices and increased fault tolerance.
Messy data
Clients may get different data in terms of quality (noisy, missing info, etc) and statistical properties (difference in distribution). That is big one and it is not easy to fix or even to detect. What is even worse, nodes with their local models can be compromised to enable a “model poisoning” attack (https://proceedings.mlr.press/v108/bagdasaryan20a.html): specially crafted data and local model updates drag the aggregated model toward an unwanted state causing erratic behavior and damage.
If you have read this far, you must share our enthusiasm for FL. If you are willing to get your hands dirty, here are some open-source FL frameworks to play with:
- FATE (https://github.com/FederatedAI/FATE) supported by the Linux Foundation.
- Substra: https://docs.substra.org/en/stable/
- PySyft + PyGrid: https://blog.openmined.org/tag/pysyft/
- Nvidia’s Clara: https://developer.nvidia.com/industries/healthcare
- IBM’s solution: https://ibmfl.mybluemix.net/
- OpenFL by Intel: https://openfl.readthedocs.io/en/latest/index.html
- and the very user friendly Flower: https://flower.dev/
If you have any questions, have interesting ideas, or just want to talk about FL, just drop a mail!