



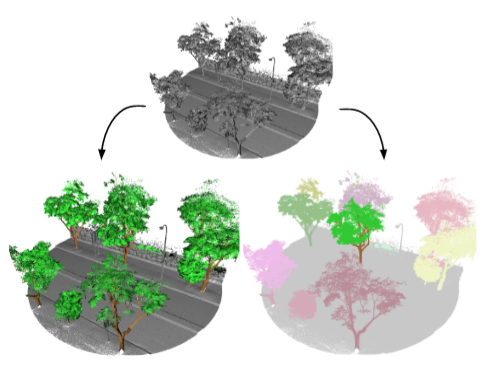
Mesterséges intelligencia a városi parkok védelmében
Technológiai forradalom zajlik körülöttünk. Az üzleti élet minden folyamatát, legyen szó marketingről, termelésről, kereskedelemről, pénzügyekről vagy logisztikáról, átalakítja a Mesterséges Intelligencia (MI) gyűjtőnévvel jellemezhető technológia, amelynek lényege, hogy megfelelő mennyiségű és minőségű adat segítségével bonyolult rendszerek is átláthatóvá, irányíthatóvá vagy legalább jósolhatóvá válnak. Azaz egy termelési vagy értékesítési lánc egyes elemeit már közösen is lehet optimalizálni, ha képesek vagyunk a megfelelő információ megszerzésére.
Mi kell ehhez? Új szemlélet, új szerveződési formák, új matematikai és informatikai megoldások.
Cégünk évek óta nyújt teljes körű IT megoldásokat különböző iparági szereplőknek. Most szintet lépünk és partnereinket már a legújabb eszközök és módszerek segítségével támogatjuk céljaik elérésében.
A következőkben bemutatjuk, hogy a legújabb MI technológiák felhasználásával, hogyan válik lehetségessé egy igen komplex feladat költséghatékony megoldása, amellyel rengeteg időt és pénzt lehet megtakarítani.
A feladat
 |
| Forrás: https://cutt.ly/vkW439J |
Megbízónk a Szingapúri Nemzeti Parkfelügyeleti Hivatallal (Singapore NParks) közösen kidolgozott egy eljárást arra,
hogy a Szingapúrt jellemző hatalmas faállományról automatikusan lehessen adatokat gyűjteni és így létrehozni egy digitális park management rendszert. (https://cutt.ly/zkKamWm )A több, mint 2 millió fa monitorozása rendkívül fontos feladat a nagy népsűrűségű városállamban, mivel a fák nem megfelelő karbantartása életeket veszélyeztethet. A fák sokfélesége és a terepi vizsgálatok nehézsége miatt a humán inspekció egyszerűen megoldhatatlan: egy szakember naponta néhány tucat fa állapotát (méret, dőlésszög, lombozat állapota, főágak elágazása) képes felmérni. Emiatt az automatizált információ rögzítés elkerülhetetlen: az adatgyűjtés során autókkal járják a várost, amelyeken speciális, nagyfelbontású lézeres térszkennelő (LIDAR) berendezés és kamerák találhatók.
Az autó pontos pozíciójával együtt a mérésekből már kirajzolódnak az egyedi fák, azaz a számítógép monitorán is elvégezhető sok mérés: a fákhoz tartozó térbeli pontok alapján meg lehet becsülni a fák lombkorona térfogatát,magasságát, a fatörzs átmérőjét, az első elágazás helyét.
E számítások alapja, hogy a rengeteg mérési pontból képesnek kell lenni pontosan elválasztani a fákhoz tartozó pontokat a háttérhez és más objektumokhoz tartozó pontoktól. Mivel rengeteg adat keletkezik, ezért a számítógépes kiértékelést sem lehet manuálisan elvégezni. Megbízónk először hagyományos – földmérők által alkalmazott – térrekonstrukciós módszerekkel próbálkozott, de az eljárás pontatlan volt és lassú.
számítások alapja, hogy a rengeteg mérési pontból képesnek kell lenni pontosan elválasztani a fákhoz tartozó pontokat a háttérhez és más objektumokhoz tartozó pontoktól. Mivel rengeteg adat keletkezik, ezért a számítógépes kiértékelést sem lehet manuálisan elvégezni. Megbízónk először hagyományos – földmérők által alkalmazott – térrekonstrukciós módszerekkel próbálkozott, de az eljárás pontatlan volt és lassú.
Forrás: https://cutt.ly/0kW4OMU
A pontatlanság fő oka az volt, hogy a rendszerük kész szabályrendszer alapján próbálta azonosítani a fákat leíró pontokat a hatalmas pontfelhő adatokban.
 |
| Ideális esetben a LIDAR által mért pontfelhő felosztható értelmes részekre: lombkorona, ágak, törzs, amiből aztán a fa teljes struktúráját meg lehet rajzolni. Forrás: https://cutt.ly/AkW4VeT |
{kind=link}
E problémát felismerve fordultak hozzánk és a mi Mesterséges Intelligencia megoldásunk valóban elérte a kívánt pontosságot és sebességet.
A feladatunk tehát a következő volt: hozzunk létre egy olyan szoftveres megoldást, aminek segítségével az elérhető 2 dimenziós (2D) képi és 3 dimenziós (3D) pontfelhő adatok alapján azonosítható a fák helye, és a fák geometriai (pl dőlésszög) és fizikai (pl magasság, átmérő) tulajdonságai automatikusan becsülhetők legyenek.
A megoldás
A minket körülvevő tér pontos ismerete, értése sokszor nélkülözhetetlen. Építészetben, épületkarbantartásban ma már természetes, hogy minden objektumról készül 3D modell is. Az orvosok egyre gyakrabban támaszkodnak 3D vizualizációs megoldásokra, amik aztán az operáció közben segítik munkájukat. Manapság pedig az önvezető autók fejlesztése miatt népszerű a térrekonstrukció. A közlekedés során fel kell ismerni rengeteg álló és mozgó objektumot (gyalogosok, közlekedési lámpa, stb) és képek alapján ez gyakran valóban nehéz vagy lehetetlen (rossz látási viszonyok, takarás).
E feladatok nehézsége az objektumok sokféleségében rejlik. Nehéz jó, szabály alapú mérnöki megoldást tervezni. Az ilyen feladatok esetében ugyanakkor az un. Gépi Tanulás (Machine Learning) megoldások meglepően jól teljesítenek.
Ezek az eljárások képesek tanulni a már korábban látott adatokból. A tanulás lényegében egy algoritmus paramétereinek a hangolását jelenti olyan módon, hogy a modell egyre pontosabban rendeljen címkéket (annotációkat) az adatokhoz. Ilyen címke a mi esetünkben például: “fatörzs”, “lombkorona”, stb. A tanító adatok lehetnek pontfelhők és a pontfelhőkhöz rendelt címkék. Ezeket a címkéket humán annotátorok készítik el. A mi esetünkben ez azt jelenti, hogy minden egyes ponthoz hozzárendelünk egy lehetőséget az előre megadott típusok közül. Egy pont lehet például háttér, fatörzs, lomb vagy egyéb vegetáció. A pontok automatikus címkézése tulajdonképpen un. szemantikus szegmentáció: az egy objektumhoz tartozó pontokat közös halmazba rakjuk. Mivel sokszor több fa is bekerül egy mérésbe, illetve a fák összeérhetnek, ezért úgynevezett egyedi szemantikus szegmentáció (‘instance segmentation’) eljárásokkal dolgoztunk. Ez a feladat annyival bonyolultabb, hogy az egy objektumhoz tartozó szegmenseket is meg kell tanulni csoportosítani. Erre a feladatra úgy válnak képessé a modelljeink, hogy az annotációt kiegészítjük az egy mintában lévő fák egyedi azonosítóival.
A megoldás menete
Adat, adat, adat
Mivel az elérhető adatbázisok a) vagy nem tartalmaznak tanító adatokat fákról b) vagy nem elég jó felbontásúak c) vagy nem elég kifinomultak az osztályok (magas és aljnövényzet), ezért első lépésben segítettünk partnerünknek egy megfelelő adatbázist létrehozni, ügyelve arra, hogy az adatok megfelelően változatosak és jó minőségűek legyenek. https://www.semantic3d.net/.
Mivel többféle szenzorral végeznek méréseket, ezért az adatbázis tartalmaz pontfelhőket és képeket is, azaz 2 és 3 dimenzióban is vizsgálhatjuk a fákat. Az ilyen bonyolult feladatok esetében tipikusan több ezres mintából álló adathalmazzal dolgozunk, azonban különböző okok miatt lényegesen kisebb tanító adathalmazt kaptunk, mint amit szükségesnek tartottunk volna. A lenti eredményeket mi néhány száz adatból tanulva kaptuk!
Tanítás
A következő lépésben tanulmányoztuk a legjobb publikált megoldásokat és választottunk néhány modellt, amelyek illeszkedtek az elérhető számítási kapacitáshoz és a tanító adatok mennyiségéhez.  Bár sokkal több kép áll rendelkezésre és a 2D szegmentációs eljárások már igen kifinomultak, a 3D adatok elemzése sokkal gyorsabb, mivel összességében kevesebb mérési pontból áll egy pontfelhő. Tanítottunk tehát 2D szegmentáló modellt a képeken, és különböző 3D modelleket az annotált 3D pontfelhőn. Az egyik modell a fa helyek azonosítását végzi (hol van a központi törzs?), míg az egyedi fák és fa-részek szegmentálására létrehoztunk egy új modellt két, korábban publikált modell összekapcsolásával.
Bár sokkal több kép áll rendelkezésre és a 2D szegmentációs eljárások már igen kifinomultak, a 3D adatok elemzése sokkal gyorsabb, mivel összességében kevesebb mérési pontból áll egy pontfelhő. Tanítottunk tehát 2D szegmentáló modellt a képeken, és különböző 3D modelleket az annotált 3D pontfelhőn. Az egyik modell a fa helyek azonosítását végzi (hol van a központi törzs?), míg az egyedi fák és fa-részek szegmentálására létrehoztunk egy új modellt két, korábban publikált modell összekapcsolásával.
A fákra hangolt 3D szegmentáló modellünk egy példa kimenete:
  |
| 3D szemantikus szegmentálás: a jobb oldali képen látható, hogy a modell szépen el tudja választani egymástól a villanyoszlopot, a fák fő ágait és a lombokat (színek jelentik az egy osztályba tartozó címkéket) |
Kiértékelés
A modellek pontosságát egy olyan annotált adatszetetten mértük le, amit a tanítás során sosem használtunk, ezzel biztosítva az objektív kiértékelést. Mivel terepi mérést nem tudtunk végezni, ezért referenciának az annotált adatokon kézzel mért értékeket vettük. Egy kis, független mintán vizsgálva a fa, illetve fa-részek szegmentálásának pontossága a következőképpen alakult:
| MIOU | Háttér | Lomb | Törzs-ág |
| 2D | 97% | 90% | 70% |
| 3D | 99% | 96% | 78% |
A kiértékelés mérő száma az un mIOU (mean intersection over union), normált átfedés a valódi és a prediktált címkék között).
A következő ábra egy tesz mintát mutat, a hozzátartozó manuális annotációt
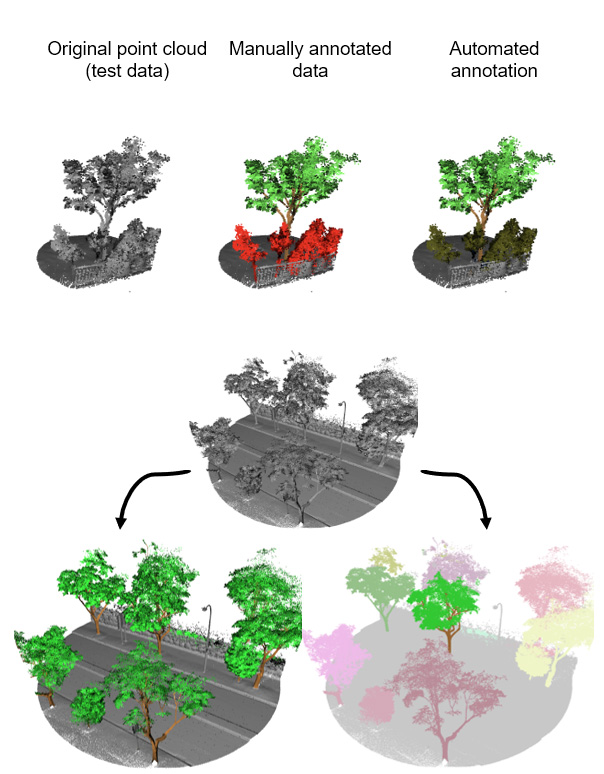 |
| (a különböző színek különböző kategóriát jelentenek: zöld: lomb, barna: fatörzs, piros: egyéb fa, szürke: háttér, egyéb objektumok) |
Megoldás integrációja
Ebben az együttműködésben az ügyfél nem teljes megoldást kívánt, hanem tanácsadást a hardver- és szoftver környezet kialakításában és támogatást az általunk létrehozott megoldás saját rendszerükbe történő integrálásához.
Az eredményül kapott integrált rendszer privát felhőben került kialakításra a végfelhasználónál, Az adatok előfeldolgozása, a modelljeink futtatása (inferencia vagy predikció) és az eredmények tárolása hatékony, elosztott rendszerben történik, ahol minden egyes lépés eredménye vizualizálható és szükség esetén kézzel korrigálható. Modelljeink tovább javíthatók, ha megnöveljük a tanító adathalmaz méretét, ezért a rendszer implementációjába bekerült egy modul, ami a nehéz eseteket gyűjti, lehetővé téve, hogy a modellt olyan adatokkal finomhangoljuk, melyeken nem működött tökéletesen vagyis a saját hibáiból tanuljon tovább.
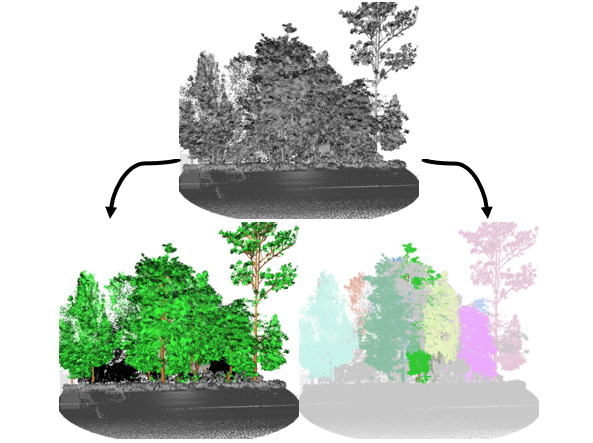 |
| A modell még a takart, összenőtt facsoportok esetében is működik, igaz, kisebb pontossággal. Itt is igaz a gépi tanulásban jól ismert tény: az MI megoldás legfeljebb annyira lesz jó, mint a tanító adat. Ebben a konkrét esetben még a humán annotátornak is gondot okozott a fák megfelelő szétválasztása. |
Miben segíthetünk?
A project során sok olyan kihívással találkoztunk, amelyek más, gyakorlati feladatokban is megjelennek: a feladat “lefordítása” az algoritmusok nyelvére, már létező megoldások elemzése, javítása, tanításhoz megfelelő adatok létrehozása. Így ez a blog talán elég érdekes és hasznos betekintést nyújt az MI ipari-üzleti alkalmazások világába.
Ha vállalkozásának van olyan komplex problémája, amelyre MI tudásunk megoldást nyújthat, akkor örömmel állunk rendelkezésére!