



Mire van szükséged? MI,ÁMI, ÉMI-re!
Cégünben folyamatosan vizsgáljuk az új IT megoldásokat, hogy a legmagasabb elvárásoknak is megfeleljünk. Ennek megfelelően nyitottunk az MI (Mesterséges Intelligencia) felé. Aktívan haszálunk és fejlesztünk MI alapú megoldásokat a legkülönfélébb üzletiés ipari területeken, legyen az biztonságtechnika, közlekedés üzemeltetés (reptéri monitorozó rendszer), viselkedés elemzés vagy ipari folyamat optimalizálás.
Mivel az MI jelenleg az egyik legforróbb hívószó, így magától adódik, hogy ez lesz első blogunk témája!
Bár rengeteg MI-vel kapcsolatos hírt olvasunk, látunk, igen sok sikertörténetről is hallani, mégis komoly zavar van a legalapvetőbb kifejezések körül is. Szintén aggódásra adhat okot, hogy a kudarcokról ritkán hallani, illetve az sem világos sokszor, mi alapján mérik az új eljárások sikerességét.
Éppen ezért mi nem beszélünk csodákról, inkább arra fókuszálunk, hogy miként lehet az üzleti szempontok figyelembevételével legjobban kihasználni az új technológiák adta előnyöket és közben a lehetséges kockázatokat hogyan tudjuk kontrollálni. Hiszünk benne, hogy az MI alapú technológiák most már szerves részévé válnak a világunknak, ugyanakkor továbbra is kritikusan állunk hozzá minden új megoldáshoz és igyekszünk transzparensen kommunikálni partnereinkkel.
Az MI-be vetett hitet tisztán mutatja a következő ábra, ami az MI alapú startup cégek globális finanszírozását mutatja az elmúlt pár évben.
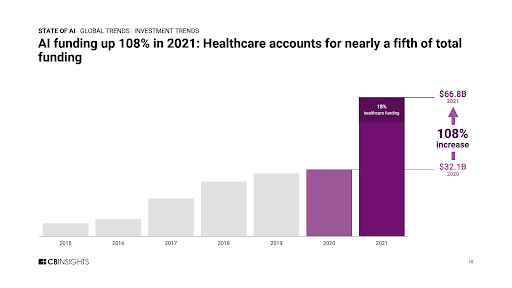 |
| Forrás: https://www.cbinsights.com/research/report/ai-trends-2021/ |
Vajon a következő dotcom válság előjeleit látjuk vagy valóban ekkora potenciál van az MI alapú technológiában?
Cégünk alkalmazott MI részlegének létezése egyértelműen bizonyítja elköteleződésünket az MI technológiákat meghatározó gondolkodás és módszertan mellett. Ez a blog pedig egy olyan témát érint, ami megmutatja, miért maradhat központi szerepben az MI az elkövetkező években is.
Mindenekelőtt tisztázzunk néhány félreértést az MI körül fogalmakkal kapcsolatban.
Mitől lesz egy rendszer MI? Egy ilyen gyakori kifejezésnél igencsak meglepő, hogy nincs tudományos konszenzus a jelentéséről. Ahhoz, hogy definiálhassuk, először tisztázni kellene, mi tesz egy természetes rendszert intelligenssé. E látszólag egyszerű kérdés megválaszolása az egyik legfontosabb célja több tudományterület kutatóinak: kognitív filozófia, számítástudomány, robotika és fejlődésbiológia mind értékes meglátásokat ad a témához. E rendkívül érdekes téma körbejárása helyett én inkább az intelligencia néhány olyan aspektusára fókuszálok most, amelyek csodálattal töltenek el minannyiunkat, amikor saját mentális képességeinkre gondolunk.
Múltbeli tapasztalataink alapján (emlékezés) képesek vagyunk felismerni és megoldani korábban látottakhoz hasonló problémákat. Komplex problémák részekre bontásával megtanuljuk, hogyan tervezzünk és készítsünk stratégiákat, amelyeket aztán jövőbeli feladatoknál tudunk hasznosítani
Emlékezés, tanulás és predikció mind szükséges az egyik legfontosabb túlélést segítő képességünkhöz, az általánosításhoz. Mi az, ami releváns, mi az, ami elfelejthető? Mi az, ami egyszeri, mi az, ami fontos, ismétlődő mintázat?
Ez a fajta általánosítóképesség, ami még mindig hiányzik a gépekből. Szóval aggódásra nincs ok, az úgynevezett általános MI (ÁMI, AGI, Artificial General Intelligence) korszaka még nem jött el. Azt gondoljuk, MI-t legtöbb esetben tévesen használják a még nem létező ÁMI-re utalva. Helyesebb lenne MI-t bizonyos feladatokra tervezett rendszerekre használni (“szűk MI”). Ebben az értelemben az MI megoldásokra úgy gondolhatunk, mint egy bizonyos kognitív képességünk gépi imitációjára. Mire gondolunk? Szövegértés, vizuális környezet modellezése, stb.
Gyakorlatilag a legtöbb MI megoldás tekinthető úgy, mint egyfajta kérdezz-felelek játék. Egy adott bemenethez (kép, szöveg, idősorok) a gép rendeljen hozzá egy “jó” választ (címke, releváns információ, predikció a következő bemenetről-megfigyelésről, stb). A kérdések és váláaszok valamilyen mintát követnek és ha elegendően sok kérdés-válasz párt mutatunk az algoritmusainknak, az MI rendszer megtanulja és felismeri a meghatározó mintázatot. Az MI ereje abban az algoritmikus képességben rejlik, hogy előre definiált szabályok vagy modellek, illetve emberi beavatkozás (instrukciók) nélkül képes e mintázatokat megtalálni és megtanulni. A megtanult minták aztán segítik a rendszert abban, hogy kitalálja hiányzó részeket, amikor a mintából csak egy rész (a kérdés) adott.
Bár nincs konszenzus az intelligencia definíciójáról, a tanulás képességét általában alapvetőnek tartják. A természet többféle mechanizmust is kifejlesztett. Beszélünk utánzás alapú, utasítás alapú vagy példa alapú tanulásról, de szintén fontos az úgynevezett kíváncsiság vezérelt (azaz külső megerősítés nélküli) tanulás is. E sokféle mechanizmus mind szükséges a túléléshez.
Jelenleg az MI algoritmusok képesek a kérdés- felelet relációt meghatározó rejtett mintázat kinyerésére valamelyik tanulási mechanizmus álta, de egyelőre nincs általános elmélet e módszerek kombinálásáról.
Azt gondolom, ez az egyik fő ok, amiért kutatók inkább gépi tanulásról (machine learning) beszélnek és kerül az MI kifejezés használatát
Bár igaz, hogy valódi MI rendszerek még nem léteznek, a gépi tanulás koncepciói igen sokat fejlődtek és a létrejött eszközök, algoritmusok igen hatékonyak a tanulásban és kevésbé probléma specifikusak. Cégünkben mi is hasonló ötleteket, eljárásokat vagyunk képesek használni igen különböző feladatokban, mint például objektum felismerés hagyományos és hőkamera képeken vagy tér szegmentálás 3D pontfelhő adatokon.
Igen sok gépi tanulás módszer ismert, amelyek különböznek az alkalmazott tanulási mechanizmusaikban, illetve abban, ahogyan kinyernek információt a prezentált adatokból. Nagy általánosságban elmondható, hogy az algoritmusok, modellek komplexitásának növelése növeli a pontosságot (nagyobb valószínűséggel ad jó választ a rendszer egy új kérdésre). De sajnos “nincsen ingyen ebéd”. A nagy, komplex modellek ritkán adnak betekintést az adatokban rejlő kapcsolatokról, valamint nem triviális megérteni, hogy jutott el a rendszer a válaszig. Másképpen mondva az értelmezhetőség valahol elveszett útközben. Egy lineáris model (tehát egy előre definiált modell, ami lineáris korrelációt tesz fel az adatokban) explicit ír le egy feltételezett összefüggést, amit aztán vagy alátámasztanak az adatok vagy nem. Ezek a komplex modellek már nem adnak közvetlen betekintést. A következő ábra sematikusan mutatja a különböző modellcsaládok átlagos teljesítménye (pontosság) és értelmezhetősége közötti kapcsolatot.
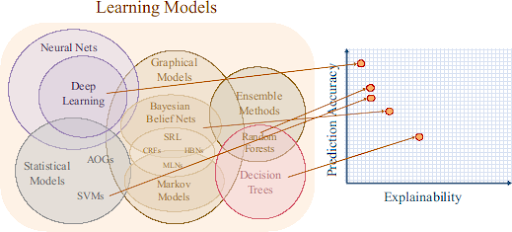
Forrás: https://www.darpa.mil/program/explainable-artificial-intelligence
Persze fel lehet tenni a kérdést, hogy miért fontos a modellek belső működésének az értése, hogyha egyszer a megoldások annyira jók.
Sok esetben talán valóban nincs ennek jelentősége, ugyanakkor érezhetően nő az érdeklődés mind a tudományban, mind az iparban a modellek értelmezhetőségével kapcsolatban. Sokan gondolják veszélyesnek, hogy az MI megoldásokat fekete dobozként kezeljük, attól félve, hogy valódi katasztrófákhoz vezethet e módszerek vak használata. Egy 2019-es PwC tanulmány [8] szerint a legtöbb megkérdezett CEO úgy gondolja, hogy az MI megoldások értelmezhetősége alapvető abban, hogy bízhassunk a hasznáatukban.
Ha nem tudjuk értelmeni, mi történik, honnan tudjuk, hogy bízhatunk-e a megoldásunkban a jövőben, amikor még nem látott helyzetek jöhetnek elő? Honnan ismerjük fel, ha a rendszer hibázik, illetve hogy mikor hibázik? Az adott feladat jobb megértése szempontjából pedig központi kérdés, hogy mit nyerhetünk az MI által megtanult mintázatokból.
Az értelmezhető MI (ÉMI, Explainable AI (XAI)) pont ezekre a kérdésekre fókuszál. Ahogy az MI eljárások használata egyre hangsúlyosabb válik, úgy lesz egyre fontosabb a megbízhatóság és elszámoltathatóság kérdése. A fenti ábra forrása a DARPA (Defence Advanced Research Projects Agency), az amerikai katonai kutatásokért felelős szervezet. Nem meglepő, hogy az elsők között voltak, akik elkezdtek komolyan foglalkozni az ÉMI kutatásával: Ha valaki, hát ők tudnak egyet s s mást a döntéshozásban használt nem átlátható módszerek kockázatáról. A katonai műveletek nem az egyetlen terület, ahol döntéshozás rengeteget nyerhet az MI megfelelő alkalmazásával. Kritikus infrastruktúrák, mint űrállomások vagy közlekedésirányítás előbb-utóbb mind MI technológiáktól fognak függni. És már most vannak olyan területek, ahogy kisebb-nagyobb problémákat okozott az MI kritikátlan használata: egészségügy (gondoljunk pl a személyreszabott gyógyításra), jog vagy biztosítás mindenképpen érintett területek.
Ráadásul a megmagyarázhatóság szorosan kötődik a személyi jogokhoz, része a GDPR-nak (‘right to explanation’), így előbb-utóbb mindenhol az értelmezhető MI megoldások kerülnek előtérbe[5].
ÉMI lényegében egy eszközkészlet, ami segít megmutatni, hogy egy adott gépi tanulás eljárás hogyan jutott az adott megoldásra. Az egyik fő cél, hogy jobban belelássunk a modellek működésébe, így a humán szakértők képessé válnak értelmezni a logikát, amit aztán a döntéshozást meghatározhatja.
Az alkalmazott MI sokfélesége miatt (alkalmazási terület, adat formák, módszerek, stb) nincs mindenki számára elfogadható univerzális megoldás. Szerencsére a nagy szervezetek döntéshozói mind erősebben állnak az új kezdeményezések mögé, így már több tucat eljárás létezik, amelyek segítségével az MI megoldások transzparens(ebb)é válnak, így növelve a bizalmat, megbízhatóságot és értelmezhetőséget. A következő ábra az ÉMI-vel kapcsolatot cikkek számát mutatja az elmúlt pár évben:
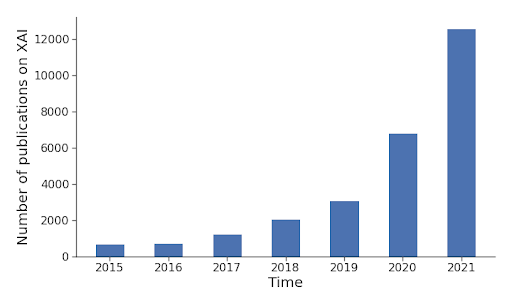 |
| Adatok forrása: shorturl.at/knAR9 |
A következő ábra az ÉMI-vel kapcsolatot cikkek számát mutatja az elmúlt pár évben:
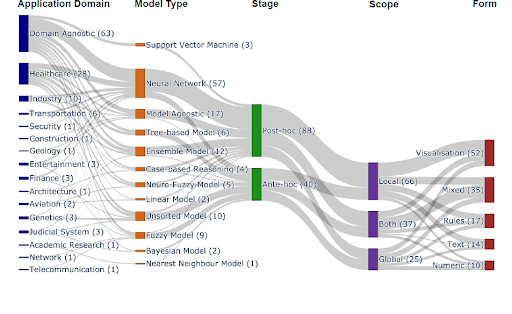 |
| Forrás: https://arxiv.org/abs/2107.07045 |
Látható, hogy sok terület-specifikus megoldás van, de általánosan használható módszerekből is egyre több érhető el. A célzott megoldási módszerek eloszlása követi a trendeket és legnagyobb számban neuronhálók (mély tanulás módszerek) szerepelnek. A legelső módszerek mind posthoc analízesre adnak módot, amivel kicsit könnyebb “belelátni” a vizsgált modellek mechanizmusába. Az újabb módszerek segítségével ugyanakkor már lehetőség van olyan modellek létrehozására melyek eleve úgy vannak tervezve, hogy az interpretációt segítsék.
Az értelmezés érvényessége alapján beszélhetünk lokális módszerekről (egy adott bemenetre adott válasz értelmezését segítik), globális módszerekről (a modellek átlagos viselkedéséről kapunk képet), illetve vannak vegyes módszerek is. Az utolsó szempont, ami alapján az ÉMI módszereit lehet csoportosítani, az a magyarázat formája.Ez azért fontos kérdés, mert a magyarázatnak ember-központúnak kellene lenni, így a prezentáció formája igencsak számít. Így beszélhetünk vizualizációs, szabály alapú, szöveg vagy numerikus módszerekről.
Az egyik ismert és népszerű model-agnosztikus eljárás, az úgynevezett LIME -Local Interpretable Model-Agnostic Explanations- [9] helyettesítő, közelítő lineáris modelleket használ, amelyek a vizsgált modell által adott válasz (predikció) és az eredeti bemenet egyes attribútumai közötti kapcsolatokat tanulják. Képek esetében ilyen tulajdonságok lehetne pixelek vagy pixelcsoportok, táblázatos adatokban az egyedi oszlopok tekinthetők attribútumoknak.
E módszer azért lett népszerű, mert sokféle általánosan használt modell esetében alkalmazható. A következő ábra egy kép osztályozási feladat megoldását elemzi. Az osztályozó egy nagy képi adatszetten lett tanítva. Sok-osztályos feladatokban gyakran a legjobb N megoldást várjuk mint kimenetet.
 |
|
Ebben az esetben az adott képhez tartozó legjobb 3 objektum címke (“levelibéka”, “billiárd asztal”, “hőlégballon”) és az azokat támogató attribútumok láthatók. Forrás: Marco Tulio Ribeiro, Pixabay (frog, billiards, hot air balloon). |
A legvalószínűbb osztály címkék a modell szerint: “levelibéka”, billiárd asztal és hőlégballon. A számok értelmezhetők valószínűségként. Tabuláris vagy egyéb struktúrált adatok esetében, ahol például az oszlopok tekinthetők egyedi tulajdonságoknak, a tulajdonságok relevanciája és kölcsönhatásaik (mennyire befolyásolják egymás előfordulását, illetve mennyire hatnak a végső válaszra) jól becsülhetők például az úgynevezett SHAP módszer segítségével (”SHapley Additive exPlanations”- [10]). – [10].
Az ismert adatelemző versenyeknek helyt adó platform, a Kaggle, egy FIFA adatsort használ a SHAP bemutatására. Több oktatóanyaguk témája az egyedi tulajdonságok elemzése. Egy példafeladatban a cél annak “jóslása”, hogy egy adott mérkőzésen melyik csapat fogja elnyerni a “meccs legjobb játékosa” díjat. Néhány felhasználható tulajdonság: ki az ellenfél, hány %-ban birtokolta a csapat a labdát, hány gólt rúgtak, stb.
A következő példa mutatja az összes tulajdonság egyedi hozzájárulását a predikciók sikerességéhez:
 |
| Forrás: https://www.kaggle.com/code/dansbecker/shap-values/tutorial |
A pirossal jelzett tulajdonságok növelik, a kék tulajdonságok csökkentik a kimeneti válasz értékét az átlagos modellválaszhoz képest. Az egyes tulajdonságok fontosságának becslésében a többi tulajdonsággal való kölcsönhatás is szerepet játszik.
 Míg az itt bemutatott példák inkább csak játékproblémák, munkánk során az értelmezhetőségnek fontos szerepe van, hiszen komplex feladatokat kell megoldanunk. Az egyik projektünkben egy többcélú, autonóm, távérzékelő rendszer kifejlesztése a feladat, amelynek célja felszíni objektumok, veszélyes tárgyak detektálása. Mivel elvárás, hogy a rendszer képes legyen működni változatos körülmények között, ezért többféle szenzor integrálására van szükség. A fejlesztendő eszköz például bevethető lehet magasan automatizált gyárakban, ahol egy leeső alkatrész vagy hibás munkadarab okozhat károkat. De kültéri alkalmazás is lehet, például repterek futópályáin és szervízplatformján már egészen apró idegen tárgyak is igen veszélyesek lehetnek. Itt az egyik fő kihívás, hogy nem tudjuk előre definiálni, mit is kellene felismerni: ezért hagyományos objektumfelismerés helyett anomália detektáláskánt értelmezzük a feladatot. Ha viszont nem tudjuk, mit keresünk, akkor könnyen elvéthetünk valamit, vagy éppen ellenkezőleg túl sokszor adunk ki téves riasztást. Biztonsági és biztosítási okoból minden eseményt rögzítünk, így képessé válunk a rendszerünk folyamatos javítására, illetve detekció magyarázatára. Így már a tervezés folyamatában a transzparenciára és megbízhatóságra tudunk fókuszálni.
Míg az itt bemutatott példák inkább csak játékproblémák, munkánk során az értelmezhetőségnek fontos szerepe van, hiszen komplex feladatokat kell megoldanunk. Az egyik projektünkben egy többcélú, autonóm, távérzékelő rendszer kifejlesztése a feladat, amelynek célja felszíni objektumok, veszélyes tárgyak detektálása. Mivel elvárás, hogy a rendszer képes legyen működni változatos körülmények között, ezért többféle szenzor integrálására van szükség. A fejlesztendő eszköz például bevethető lehet magasan automatizált gyárakban, ahol egy leeső alkatrész vagy hibás munkadarab okozhat károkat. De kültéri alkalmazás is lehet, például repterek futópályáin és szervízplatformján már egészen apró idegen tárgyak is igen veszélyesek lehetnek. Itt az egyik fő kihívás, hogy nem tudjuk előre definiálni, mit is kellene felismerni: ezért hagyományos objektumfelismerés helyett anomália detektáláskánt értelmezzük a feladatot. Ha viszont nem tudjuk, mit keresünk, akkor könnyen elvéthetünk valamit, vagy éppen ellenkezőleg túl sokszor adunk ki téves riasztást. Biztonsági és biztosítási okoból minden eseményt rögzítünk, így képessé válunk a rendszerünk folyamatos javítására, illetve detekció magyarázatára. Így már a tervezés folyamatában a transzparenciára és megbízhatóságra tudunk fókuszálni.
Bízunk benne, ez a kis összefoglaló is segít, hogy erősítse a bizalmat a modern MI megoldások felé, így segítve vállakozásunkat innovatív és kreatív megoldásokkal. Reméljük, segíthetjük vállalkozása növekedését (É)MI tapasztalatunkkal!
Bízunk benne, ez a kis összefoglaló is segít, hogy erősítse a bizalmat a modern MI megoldások felé, így segítve vállakozásunkat innovatív és kreatív megoldásokkal. Reméljük, segíthetjük vállalkozása növekedését (É)MI tapasztalatunkkal!
A következő posztjainkban bemutatjuk azokat a területeket, projekteket, melyeken aktív kutatási és fejlesztési tevékenységet folytatunk.
Hivatkozások:
[2] Gunning, D., Vorm, E., Wang, J.Y. and Turek, M. (2021), DARPA’s explainable AI (XAI) program: A retrospective. Applied AI Letters, 2: e61. https://doi.org/10.1002/ail2.61
[3] http://www-sop.inria.fr/members/Freddy.Lecue/presentation/aaai_2021_xai_tutorial.pdf
[4] https://proceedings.neurips.cc//paper/2020/file/2c29d89cc56cdb191c60db2f0bae796b-Paper.pdf
[5] Recital 71 eu gdpr. https://www.privacy-regulation.eu/en/r71.htm, 2018. Online; accessed 27-May-2020.
[6] https://proceedings.neurips.cc//paper/2020/file/2c29d89cc56cdb191c60db2f0bae796b-Paper.pdf
[7] Gohel, Prashant et al. “Explainable AI: current status and future directions.” ArXiv abs/2107.07045 (2021).
[8] https://www.computerweekly.com/news/252462403/Bosses-want-to-see-explainable-AI
[9] Ribeiro MT, Singh S, Guestrin C (2016) “Why should I trust you?” Explaining the predictions of any classifier. In: Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pp 1135–1144
[10] Scott M. Lundberg and Su-In Lee. 2017. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 4768–4777.