



Wszystko czego potrzebujesz to AI, AGI? XAI! (ang. eXplainable AI)
W ISRV poszukujemy stale najlepszych narzędzi IT aby móc zaspokoić najwyższe wymagania naszych klientów. Dlatego właśnie zajmujemy się sztuczną inteligencją (ang. artificial intelligence, AI). Cały czas aktywnie używamy i rozwijamy narzędzia wykorzystujące AI w różnych dziedzinach: od rozwiązań związanych z zapewnieniem bezpieczeństwa ruchu (w szczególności, dla pasów startowych na lotniskach), poprzez analizy wzorców zachowania ludzi, aż do usprawniania procesów przemysłowych i biznesowych.
Sztuczna inteligencja (AI) jest dziś słowem kluczem, znakiem naszych czasów, dlatego naturalnym jest, że zajmuje ona centralne miejsce na naszym blogu.
Media są pełne doniesień na temat AI, pełne przykładów niesamowitych sukcesów, jednak w dalszym ciągu istnieje wiele nieporozumień dotyczących znaczenia podstawowych pojęć tej dziedziny. Alarmujące jest również to, że zazwyczaj nie opowiada się o odniesionych porażkach, nie jest też do końca jasne w jaki sposób mierzy się sukces w dziedzinie zastosowań AI. Nie zamierzamy tutaj mówić na temat sukcesów i cudownych zastosowań AI.
Zamiast tego chcemy skupić się na tym jak wypełnić lukę między biznesem a technologią. Wierzymy, że AI pozostanie z nami i stanie się stałym składnikiem ekosystemu IT, ale wierzymy również, że jasna komunikacja z naszymi klientami oraz krytyczne podejście do technologii jest szczególnie istotne.
O dynamice rozwoju sztucznej inteligencji świadczy chociażby dobitnie sama ilość pieniędzy wydanych na finansowanie startupów opartych na sztucznej inteligencji. Pokazuje to poniższy wykres.
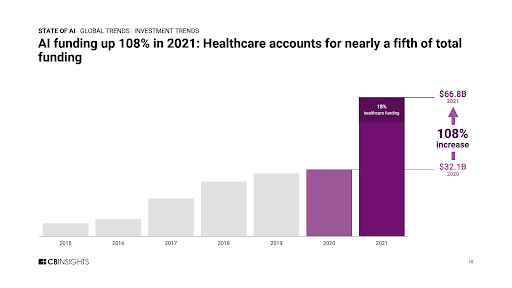 |
| Źródło: https://www.cbinsights.com/research/report/ai-trends-2021/ |
Nasuwa się tutaj pytanie: czy to tylko preludium do kolejnej bańki inwestycyjnej, podobnej do bańki internetowej (tzw. dot-com bubble) z końca lat 90-tych?
Już samo istnienie wydziału sztucznej inteligencji w naszej firmie świadczy o tym, że bardzo poważnie podchodzimy i do metodologii w tej dziedzinie, i do jej zastosowań. Nasz blog podkreśla jeden kluczowy czynnik, który powoduje, że uważamy AI za technologię, która pozostanie z nami na długi czas.
Po pierwsze wyjaśnijmy zamieszanie wokół terminów „sztuczna inteligenacja” (ang. Artificial intelligence, AI) i „uczenie maszynowe” (ang. machine learning, ML). Co powoduje, że system jest „systemem AI”, systemem sztucznej inteligencji? Biorąc pod uwagę ogromną popularność tego terminu, może być zaskakujące, że w świecie nauki nie ma zgody co do znaczenia pojęcia „sztuczna inteligencja”. Abyśmy mogli zdefiniować to pojęcie, musielibyśmy zdefiniować najpierw co powoduje, że uważamy jakiś naturalny system za inteligentny. Odpowiedź na takie pozornie proste pytanie jest „świętym Graalem” tej dziedziny, jest przedmiotem wielu dyskusji specjalistów z różnych dziedzin, takich jak: psychologia kognitywna, informatyka, robotyka czy nauki o rozwoju człowieka. Jednak zamiast poszukiwać odpowiedzi na to, skądinąd fascynujące pytanie, skupimy się tutaj na pewnych aspektach inteligencji, które mogą nas samych zadziwiać, gdy myślimy o naszych ludzkich zdolnościach umysłowych.
Pamiętając o tym czego doświadczyliśmy w przeszłości, możemy rozpoznać i rozwiązać problemy podobne do tych, które poznaliśmy wcześniej. Poprzez dekompozycję dużych problemów na mniejsze uczymy się jak tworzyć plany i strategie, które będą przydatne w rozwiązywaniu przyszłych problemów.
Połączenie takich czynności jak: zapamiętywanie, uczenie się czy przewidywanie jest podstawą umiejętności uogólniania, umiejętności, której wciąż brakuje maszynom. Dla tego na razie nie musimy się martwić, era tzw. ogólnej sztucznej inteligencji (ang. artificial general intelligence, AGI) jeszcze nie nadeszła.
Sądzimy, że w większości przypadków termin „sztuczna inteligencja” jest niewłaściwie użyty, szczególnie gdy odnosi się do nie istniejącej przecież jeszcze „ogólnej sztucznej inteligencji” (AGI). Zamiast tego uważamy, że termin AI powinien być używany dla systemów zaprojektowanych do rozwiązywania pewnego wybranego problemu (tzw. „narrow AI”). Można powiedzieć, że w tym sensie dane rozwiązanie AI będzie imitować pewien wybrany proces poznawczy, proces kognitywny, taki jak na przykład rozumienie tekstu czy rozumienie sceny.
Z naszego punktu widzenia pojęcie sztuczna inteligencja (AI) będzie najczęściej oznaczało po prostu system informatyczny przeznaczony do rozwiązywania pewnych problemów wymagających technik uczenia maszynowego. W praktyce, większość rozwiązań AI może być rozpatrywana jako gra typu pytanie-odpowiedź: dla określonych danych wejściowych (takich jak obraz, tekst czy dane liczbowe np. szeregi czasowe) należy przypisać odpowiednią etykietę (ang. label). Będzie to na przykład: adnotacja tekstowa, powiązana z danymi informacja lub przewidywanie dotyczące następnej wartości w szeregu czasowym, itd. Pytania i odpowiedzi mogą być zgodne z pewnym nieznanym wzorcem, trudnym do zdefiniowania jako prosty model matematyczny. Jednak, gdy systemowi zostanie przedstawiona wystarczająca (zazwyczaj bardzo duża) liczba takich par: pytanie-odpowiedź, to system może nauczyć się rozpoznawać ten specyficzny wzorzec. Potęga sztucznej inteligencji polega na możliwości znajdowania i uczenia się tych wzorców bez udziału człowieka oraz bez znajomości predefiniowanych modeli, pojęć czy idei. Wyuczone wzorce następnie prowadzą system do odgadnięcia brakujących części, gdy prezentowany jest jeden element wzorca („pytanie”). Uczenie się jest kluczową koncepcją inteligencji, dlatego natura wyposażyła nas w kilka możliwości uczenia się: poprzez naśladowanie, uczenie się oparte na instrukcjach, uczenie się z przykładów oraz uczenie się oparte na ciekawości. Wszystkie te sposoby uczenia się są potrzebne by dać organizmowi większe szanse na przetrwanie w środowisku. Systemy informatyczne AI potrafią wydobyć te ukryte informacje dotyczące relacji pytanie-odpowiedź za pomocą jednego z podanych mechanizmów uczenia się. Oznacza to, że często rozwiązać problem można na kilka sposobów, na przykład stosując różne metody uczenia maszynowego. Jednak nie istnieje na razie ogólna teoria pozwalająca na stworzenie systemu stosującego kombinację tych podejść. Jest to prawdopodobnie powód tego, że większość naukowców i specjalistów IT mówiąc o sztucznej inteligencji mówi najczęściej o uczeniu maszynowym a nie o ogólnej sztucznej inteligencji.
Chociaż prawdą jest to, że sztuczna inteligencja jeszcze się nie pojawiła, to jednak istnieją już gotowe zestawy narzędzi uczenia maszynowego w postaci bibliotek oprogramowania, które są niezwykle efektywne w szczególnych zastosowaniach. W firmie Polaris i ISRV stosujemy te narzędzia do rozwiązywania różnorodnych zadań i problemów, takich jak np. wykrywanie obiektów na obrazach RGB i na obrazach w podczerwieni (termowizja) oraz wykonywanie segmentacji na chmurach punktów 3D.
Istnieje wiele różnych modeli uczenia maszynowego. Różnią się one mechanizmami uczenia oraz sposobem opisu problemu, który przesyłamy komputerowi do rozwiązania.
Ogólnie rzecz biorąc, większa złożoność modelu skutkuje większą dokładnością (czyli wyższym prawdopodobieństwem udzielania poprawnej odpowiedzi).
Ale nie ma nic za darmo: zastosowane modele, choć są bardzo skomplikowane, to nie mogą dać nam wglądu w zależności znalezione w danych, nie mogą dać nam też wglądu w to, jak model doszedł do ostatecznego wyniku, do końcowego wniosku jego analiz.
Innymi słowy, tzw. „wyjaśnialność” modelu gdzieś się po drodze gubi.
Poniższy rysunek przedstawia związek pomiędzy średnią wydajnością (czyli dokładnością) modelu a jego wyjaśnialnością .
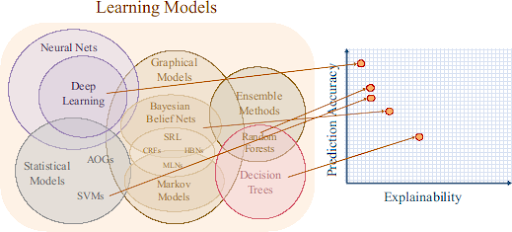
Źródło: https://www.darpa.mil/program/explainable-artificial-intelligence
Można by w tym miejscu zapytać, dlaczego tak istotna jest możliwość zrozumienia wewnętrznych procesów jakie zachodzą w tych złożonych modelach, skoro końcowy rezultat ich pracy jest taki dobry. Czasem można spotkać się z poglądem, że nie ma to znaczenia, skoro tak dobrze działają. Jednak coraz częściej i w środowiskach akademickich i w przemyśle wzrasta zainteresowanie tą kwestią. Ponieważ modele te są coraz częściej stosowane w różnych dziedzinach życia i coraz więcej stają się ważnym elementem kluczowych procesów, dlatego wielu specjalistów uważa, że nie można ich traktować jak „czarnej skrzynki” i interesować się tylko ostatecznym wynikiem. Takie podejście jest niebezpieczne i może w przyszłości prowadzić do różnego rodzaju nieprzewidzianych skutków czy wręcz katastrof. Wg badań PwC z 2019r [8] większość ankietowanych dyrektorów generalnych (CEO) uważa, że sztuczna inteligencja musi być wyjaśnialna aby można było jej zaufać.
Jeżeli nie potrafimy wyjaśnić co się dzieje wewnątrz pewnego systemu, to jak możemy mu zaufać w przyszłości? Skąd mamy wiedzieć, czy taki system zawiedzie albo kiedy zawiedzie? Co możemy uzyskać z wyuczonych wzorców?
Pojęcia takie jak wyjaśnialność modelu czy w ogóle wyjaśnialna sztuczna inteligencja (XAI) dotyczą właśnie takich problemów. W miarę jak wzrasta wykorzystanie sztucznej inteligencji, jest coraz więcej obszarów, w których wiarygodność metody i odpowiedzialność za wynik mają centralne znaczenie. Źródłem poprzedniego wykresu jest DARPA (Agencja Zaawansowanych Projektów Badawczych w Obszarze Obronności), organizacja odpowiedzialna za badania militarne w Stanach Zjednoczonych. Nic dziwnego, że to właśnie ta organizacja była jedną z pierwszych organizacji zajmujących się bardzo poważnie problemem wyjaśnialności w dziedzinie sztucznej inteligencji. Branża militarna nie jest jedyną branżą, w której podejmowanie decyzji może być usprawnione dzięki użyciu systemów AI. Pewnego dnia infrastruktura o krytycznym znaczeniu jak na przykład statki kosmiczne czy kontrola ruchu lotniczego będą zależeć od sztucznej inteligencji. Już dziś istnieją dziedziny, gdzie doświadczamy mniejszych lub większych przeszkód związanych ze krótkowzrocznym używaniem metod sztucznej inteligencji jako tzw. „czarnej skrzynki”. Przykładami mogą być: opieka zdrowotna (pomyślmy choćby o spersonalizowanej medycynie), prawo czy sektor ubezpieczeń.
Dodatkowo, wyjaśnialność jest powiązana również z zachowaniem prywatności (RODO, czyli tzw. Prawo do wyjaśnienia), tak więc pomału nieodwołalna staje się konieczność wykorzystania wyjaśnialnych rozwiązań AI.
Przez wyjaśnialną sztuczną inteligencję (XAI) rozumie się zestaw narzędzi, za pomocą których można pokazać w jaki sposób dane modele uczenia maszynowego podejmują decyzje. Celem jest zapewnienie wglądu w sposób działania modelu, tak aby człowiek, ekspert w tej dziedzinie mógł prześledzić proces podejmowania decyzji i zrozumieć logikę jaka za nim stoi.
W związku różnorodnością w dziedzinie AI, w tym z różnorodnością dziedzin zastosowań, typów danych, metod i zakresu, nie istnieje jedno uniwersalne podejście do wyjaśnialnej sztucznej inteligencji (XAI).
Jednak dzięki coraz większej świadomości interesariuszy w różnych organizacjach istnieją dziesiątki nowych metod, które pomagają przekształcić „niewyjaśnialne” metody sztucznej inteligencji w wyjaśnialne. Takie, które będą bardziej przejrzyste, przewidywalne i pewne, i którym można zaufać. Poniższy wykres przedstawia liczbę opublikowanych raportów na temat wyjaśnialnej sztucznej inteligencji (XAI) w ciągu ostatnich kilku lat.
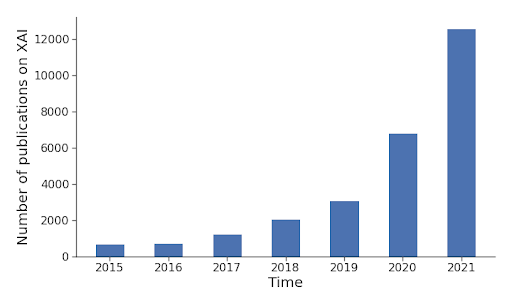 |
| Źródło: shorturl.at/knAR9 |
Niedawno opublikowany przegląd dotyczący analizy artykułów na temat wyjaśnialnej sztucznej inteligenacji (XAI) opublikowanych w renomowanych czasopismach naukowych zawierał następujące zestawienie przedstawiające zastosowania różnych metod XAI. Wyniki możemy zobaczyć poniżej.
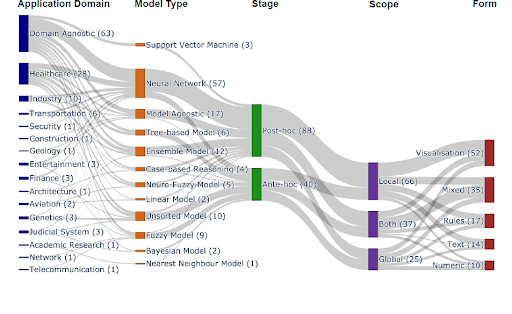 |
| Źródło: https://arxiv.org/abs/2107.07045 |
Jak widać na powyższym wykresie, istnieje wiele metod specyficznych dla danej dziedziny, ale widać też, że duża liczba metod może być stosowana uniwersalnie. Widać też, że rozkład podstawowych metod uczenia maszynowego jest zgodny z obecnymi trendami widocznymi dziedzinie AI, z głębokimi sieciami neuronowymi (DLN) na czele. Tradycyjnie łatwiej jest przeprowadzić analizę post hoc i zajrzeć w mechanizm zastosowanych modeli. Niemniej jednak nowe pomysły pomagają tworzyć nowe rozwiązania, które po prostu ze swej natury będą wyjaśnialne. Badanie wyjaśnialności polega na tym, że analizuje się odpowiedzi na pojedyncze dane wejściowe lub też analizuje się przeciętne zachowanie systemu pod wpływem tych danych. Ostatecznie wynik tego procesu powinien być skoncentrowany na człowieku – dlatego sposób w jaki ten wynik jest prezentowany ma znaczenie. Tak więc metody te charakteryzują się tym, że dają wyniki w formie wizualizacji, zasad, tekstu czy liczb.
Oto przykłady metod lokalnych, czyli takich, gdzie można interpretować wyjście modelu do danej instancji. Oprócz tego istnieją również metody globalne oraz mieszane. Większość z nich można zastosować do innych modalności takich jak tekst, dźwięk czy dane multimodalne.
Metoda LIME (Local Interpretable Model-Agnostic Explanations) – to metoda obojętna względem modelu, tworzy zastępczy model liniowy, który uczy się związku pomiędzy predykcją modelu źródłowego a cechami oryginalnego sygnału wejściowego. Dla obrazów cechami mogą być piksele lub ich grup, dla danych tabelarycznych cechami będą oddzielne kolumny. Ta metoda zyskała popularność, ponieważ może być stosowana dla wielu różnych modeli i metod.
W problemach klasyfikacyjnych, gdzie występuje wiele klas, modele są często używane, aby dostarczyć jako wynik nie jedną, a pewną liczbę N najwyżej ocenianych etykiet (ang. labels) dla podanych danych wejściowych. Przykład pokazany na poniższym rysunku analizuje trzy główne (tzn. najwyżej oceniane) etykiety (odpowiadające trzem przewidywanym przez model klasom).
 |
|
Trzy główne przewidywane przez model klasy to „tree frog”, pool table” i „balloon”. Źródła: Marco Tulio Ribeiro, Pixabay (frog, billiards, hot air balloon). |
Dla danych tabelarycznych lub ustrukturyzowanych, gdzie kolumny reprezentują atrybuty lub zdefiniowane cechy, ważność cech oraz proste interakcje pomiędzy cechami można oszacować i zwizualizować używając na przykład metody SHAP (SHapley Additive exPlanations) Zaprezentowanej w racy [10]. [10].
Na przykład Kaggle używa zestawu danych FIFA, który zawiera dane o kilku meczach. Kilka dostępnych tam tutoriali dotyczy problemu analizy ważności poszczególnych cech podczas procesu przewidywania przez model czy dana drużyna zdobędzie odznakę „Man of the Match”. Wśród nich są takie cechy jak: drużyna przeciwnika, posiadanie piłki, zdobyte gole, itd.
Poniższy przykład pokazuje udział każdej z cech w ostatecznym wyniku (czyli predykcji) generowanej przez model.
 |
| Źródła: https://www.kaggle.com/code/dansbecker/shap-values/tutorial |
Cechy zaznaczone na czerwono zwiększają, natomiast cechy zaznaczone na niebiesko zmniejszają przewidywany wynik z uśrednionego wyjścia modelu. Podczas obliczania ważności cech brane są również pod uwagę interakcje pomiędzy nimi.
 Choć podane przykłady można uznać za uproszczone czy edukacyjne, to pokazany problem wyjaśnialności modelu ma tutaj kluczowe znaczenie. Wyobraźmy sobie, że pracujemy nad wielofunkcyjnym autonomicznym urządzeniem do teledetekcji, urządzeniem, które może być wykorzystane do detekcji obcych obiektów lub anomalii na pewnej badanej powierzchni. Aby zapewnić odpowiednią skuteczność działania, urządzenie wyposażono w wiele czujników. Pomyślmy na przykład o wykrywaniu różnych luźnych elementów w wysoce zautomatyzowanej fabryce albo o wykrywaniu gruzu na pasach startowych lotnisk. Wyzwanie polega na tym, że nie możemy z góry określić czego szukamy, ponieważ anomalia jest tylko odchyleniem od oczekiwań. Z kolei system może „przegapić” coś ważnego albo też wywołać fałszywy alarm. Ze względów bezpieczeństwa oraz dla celów ubezpieczeniowych rejestrujemy wszystkie zdarzenia, po to abyśmy mogli rozwiązać problem lub wyjaśnić uzyskane wyniki. Dzięki temu nasze rozwiązania są z założenia transparentne i godne zaufania.
Choć podane przykłady można uznać za uproszczone czy edukacyjne, to pokazany problem wyjaśnialności modelu ma tutaj kluczowe znaczenie. Wyobraźmy sobie, że pracujemy nad wielofunkcyjnym autonomicznym urządzeniem do teledetekcji, urządzeniem, które może być wykorzystane do detekcji obcych obiektów lub anomalii na pewnej badanej powierzchni. Aby zapewnić odpowiednią skuteczność działania, urządzenie wyposażono w wiele czujników. Pomyślmy na przykład o wykrywaniu różnych luźnych elementów w wysoce zautomatyzowanej fabryce albo o wykrywaniu gruzu na pasach startowych lotnisk. Wyzwanie polega na tym, że nie możemy z góry określić czego szukamy, ponieważ anomalia jest tylko odchyleniem od oczekiwań. Z kolei system może „przegapić” coś ważnego albo też wywołać fałszywy alarm. Ze względów bezpieczeństwa oraz dla celów ubezpieczeniowych rejestrujemy wszystkie zdarzenia, po to abyśmy mogli rozwiązać problem lub wyjaśnić uzyskane wyniki. Dzięki temu nasze rozwiązania są z założenia transparentne i godne zaufania.
Sądzimy, że ten krótki tekst poprzez zasygnalizowanie kilku ważnych kwestii pomoże budować zaufanie do transparentnych rozwiązań w dziedzinie AI. Możliwość wyjaśnienia, dlaczego systemy AI działają w taki a nie inny sposób, dlaczego dają określone wyniki, pomoże tworzyć innowacyjne i wiarygodne rozwiązania zarówno dla starych, jak i dla nowych problemów.
Mamy nadzieję, że dzięki naszemu doświadczeniu oraz naszej pasji będziemy mogli pomóc Państwa firmie rozwijać się i wykorzystać szanse jakie daje sztuczna inteligencja.
W kolejnych postach przedstawiamy obszary i projekty, w których aktywnie działamy w zakresie badań i rozwoju.
Źródła:
[2] Gunning, D., Vorm, E., Wang, J.Y. and Turek, M. (2021), DARPA’s explainable AI (XAI) program: A retrospective. Applied AI Letters, 2: e61. https://doi.org/10.1002/ail2.61
[3] http://www-sop.inria.fr/members/Freddy.Lecue/presentation/aaai_2021_xai_tutorial.pdf
[4] https://proceedings.neurips.cc//paper/2020/file/2c29d89cc56cdb191c60db2f0bae796b-Paper.pdf
[5] Recital 71 eu gdpr. https://www.privacy-regulation.eu/en/r71.htm, 2018. Online; accessed 27-May-2020.
[6] https://proceedings.neurips.cc//paper/2020/file/2c29d89cc56cdb191c60db2f0bae796b-Paper.pdf
[7] Gohel, Prashant et al. “Explainable AI: current status and future directions.” ArXiv abs/2107.07045 (2021).
[8] https://www.computerweekly.com/news/252462403/Bosses-want-to-see-explainable-AI
[9] Ribeiro MT, Singh S, Guestrin C (2016) “Why should I trust you?” Explaining the predictions of any classifier. In: Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pp 1135–1144
[10] Scott M. Lundberg and Su-In Lee. 2017. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 4768–4777.