



Nie wpuszczaj Wielkiego Brata! – Bezpieczeństwo i prywatność w opiece nad osobami starszymi
W naszym poprzednim poście mówiliśmy o tym, że opieka nad osobami starszymi staje się jednym z najbardziej podstawowych wyzwań na całym świecie. Jest oczywiste, że będziemy potrzebować wszystkich możliwości, jakie może zaoferować IT, czy to chmury obliczeniowej, urządzeń brzegowych (tzw. edge devices), urządzeń wbudowanych (tzw. embedded devices) czy sztucznej inteligencji (artificial intelligence, AI). Jednak nawet te najnowocześniejsze, najświeższe nowe technologie nie są pozbawione poważnych wad, które mogą poważnie zagrozić bezpieczeństwu ludzi. Niewłaściwie użyte mogą nieść ryzyko utraty prywatności, powstania szkód materialnych czy nawet stwarzać zagrożenie dla życia lub zdrowia. W przypadku osób starszych ryzyko będzie zazwyczaj jeszcze większe.
Wyobraźmy sobie taką sytuację. Myślisz, że twoja babcia ma się dobrze, ponieważ jej stan zdrowia i samopoczucie jest stale monitorowane. Odpowiednie systemy monitorują co się dzieje z wybraną osobą w domu (za pomocą kamer, lidarów itp.) oraz na zewnątrz (np. za pomocą urządzeń ubieralnych takich jak urządzenia elektroniczne, które nosi się na ciele np. opaski i smartwatche itp.). Ale wyobraź sobie co może się stać, gdy komunikacja tych urządzeń nie będzie odpowiednio zabezpieczona i ktoś obcy będzie mógł zobaczyć, kiedy np. mieszkanie jest puste, lub w jakich godzinach ktoś śpi. Możliwa jest też np. kradzież danych biometrycznych, które służą do identyfikacji osoby, a wtedy łatwym zadaniem staje się ukraść pieniądze czy popełnić oszustwo obciążając nim niewinną osobę. Wyobraź sobie jeszcze gorszą sytuację, gdy ktoś może zmieniać ustawienia urządzeń medycznych takich jak inteligentny rozrusznik serca lub pompa insulinowa. Takie wypadki są możliwe i już się zdarzały! shorturl.at/bkrX2).
Kwestie bezpieczeństwa i zapewnienia prywatności (bezpieczeństwo fizyczne i cyfrowe) są dobrym tematem na oddzielny post. Teraz jednak chcemy przedstawić Wam inny aspekt prywatności: uczenie się z wysoce wrażliwych danych. Jest to temat związany z tworzeniem rozproszonych modeli sztucznej inteligencji, które uczą się korzystając intensywnie z danych dostarczanych z wielu źródeł, np. z wielu telefonów komórkowych (często od osób, które nie zawsze zdają sobie z tego sprawę).
Jak już wcześniej pisaliśmy, dane są niezwykle ważne do tworzenia i trenowania modeli sztucznej inteligencji, dlatego nie powinno dziwić nas, że systemy monitorujące zdrowie i modelujące zachowania wymagają bardzo dużej ilości danych. Dane te mogą być bardzo różnorodne: bardzo proste jak np. liczba kontaktów lekarza z pacjentem w miesiącu lub tak złożone, jak zmienność rytmu serca sekunda po sekundzie. Często dane, zwłaszcza te skomplikowane, muszą być przetwarzane na zdalnych serwerach (w tzw. chmurze) czyli muszą być przesłane siecią poza urządzenie, które je pobierało. Problem polega na tym, że musimy się upewnić, że żadne informacje osobiste (tzw. „metadane”) nie zostaną wymieszane z danymi wysyłanymi dalej, potrzebnymi do trenowania modeli sztucznej inteligencji. Dlaczego tak jest? Otóż udostępnienie tak wrażliwych danych może stanowić bezpośrednie zagrożenie dla uczestników całego procesu (np. pacjentów). Co więcej, istnieje ryzyko pośrednie, ponieważ można zaszkodzić nawet tym, którzy nie dostarczają własnych danych do procesu trenowania modeli, ale są w pewien sposób związani z pacjentami.
W przypadku monitorowania zdrowia problem nie ogranicza się do fazy trenowania modelu. Ciągłe monitorowanie pacjentów wymaga ciągłego utrzymania kontaktu i wielokrotnego dostępu do wrażliwych danych. Dane te są następnie wykorzystywane do dostarczania prognoz, ale także niezbędnych informacji do ciągłej aktualizacji (tzw. fine tuning) modeli uczących się (tzw. scenariusz ciągłego uczenia się). Jak więc możemy zabezpieczyć przepływ wrażliwych danych? Jak możemy się upewnić, że wrażliwe dane osobowe nie dostaną się w niepowołane ręce?
Istnieje kilka podejść. Są na przykład rozwiązania, które albo próbują ukryć lub wymazać wrażliwe informacje (poprzez różnego rodzaju tzw. anonimizację danych), albo takie które polegają na szyfrowaniu kanału komunikacyjnego.
Jest jednak jeszcze jeden bardzo ciekawy pomysł, który może sprawić, że przesyłanie wrażliwych informacji w ogóle nie będzie konieczne. To podejście nazywa się federated learning (FL) co można przetłumaczyć jako uczenie federacyjne, czyli uczenie jednoczące wiedzę pochodzącą z różnych źródeł. Zobaczmy, o co w tym wszystkim chodzi.
Federated Learning (FL)
Według Wikipedii: „Uczenie federacyjne to technika uczenia maszynowego, która trenuje model wykorzystując dane przechowywane w wielu zdecentralizowanych urządzeniach brzegowych lub serwerach przechowujących lokalne próbki danych, bez ich przesyłania czy wymiany. Uczenie federacyjne umożliwia wielu podmiotom budowanie wspólnego, wydajnego modelu uczenia maszynowego bez współdzielenia danych, co pozwala na rozwiązanie krytycznych kwestii cyberbezpieczeństwa, takich jak prywatność i bezpieczeństwo danych, prawa dostępu do danych i dostęp do danych heterogenicznych. Jego zastosowania obejmują wiele branż, w tym obronność, telekomunikację, IoT, farmację. ”
Termin ten został wprowadzony przez firmę Google jeszcze w 2017 roku. (https://arxiv.org/abs/1602.05629v3)
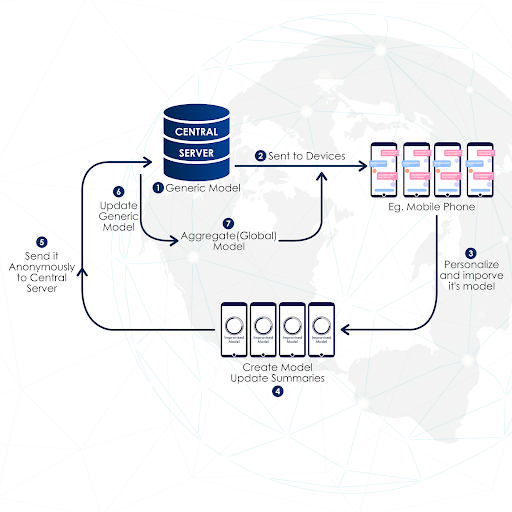 |
Przyjrzyjmy się jednak dokładniej tej złożonej definicji. Pierwszą interesującą technologią jest uczenie rozproszone.. Aby uzupełnić naszą wiedzę, porozmawiajmy trochę o uczeniu maszynowym (machine learning, ML), w szczególności o uczeniu nadzorowanym. W przypadku tego rodzaju uczenia zadanie polega na nauce kojarzenia tzw. etykiet (labels) z danymi. Te algorytmy uczenia maszynowego uczą się odpowiednich skojarzeń (czyli przypisania etykiety do analizowanych danych) poprzez przyrostowe dostrajanie bardzo wielu parametrów, które definiują łańcuch przekształceń tworzących algorytm. Przykładem są choćby dzisiejsze głębokie sieci neuronowe. W ich przypadku mówimy o milionach lub miliardach parametrów! To wyjaśnia, dlaczego proces trenowania modelu (w tym wypadku opartego na sieci neuronowej) jest tak żmudny w większości przypadków. Jeśli jednak kilka maszyn może równolegle pracować na różnych ‘porcjach’ danych, to trenowanie modelu staje się znacznie szybsze, o ile oczywiście wytrenowane fragmenty modelu są odpowiednio połączone w jedno rozwiązanie, w jeden główny model. Szybkość, decentralizacja to jedna z zalet. Drugą, nie mniej ważną jest ochrona prywatności. Idea polega na zminimalizowaniu wymiany danych pomiędzy klientami (czyli urządzeniami, która mogą trenować model, a właściwie jego fragment, na lokalnych danych) a serwerem (urządzeniem, które agreguje cząstkowe modele, lokalne aktualizacje modeli, organizuje wymianę parametrów, ale nie ma dostępu do lokalnych danych trenujących u klientów). Ta konkretna cecha, jest na tyle ważną zaletą, że czyni uczenie federacyjne (FL) centralną częścią wszystkich aplikacji AI w przemyśle i biznesie: Google, IBM, Intel, Baidu czy Nvidia opracowały swoje własne frameworki FL klasy korporacyjnej! ( shorturl.at/dgiy7)!
Oryginalny pomysł opierał się na założeniu, że urządzenia brzegowe (takie jak smartfony) mogą zarówno zbierać, jak i przetwarzać dane lokalnie. Z kolei, jeśli modele mogą zmieścić się w pamięci telefonu, to wystarczy wymienić lokalne aktualizacje modelu z centralnym modelem. Koncepcja ta nosi nazwę cross-device FL. Spersonalizowany texting, taki jak np. Gboard, wykorzystuje to podejście.
Cóż, pisanie tekstów na telefonach komórkowych jest w porządku, ale pomiar cukru we krwi? W tym przypadku możliwy inny realny scenariusz. Załóżmy, że już podzieliłeś się swoimi danymi medycznymi z lekarzem, tak jak wszyscy inni pacjenci. Jest to normalna procedura w każdym ośrodku zdrowia. Z kolei ośrodek zdrowia może dostroić własny model, wykorzystując wszystkie dostępne dane swoich pacjentów. Dalej: różne ośrodki zdrowia mogą wymieniać parametry modelu bez narażania wrażliwych danych swoich pacjentów. Takie podejście nazywa się cross-silo FL.
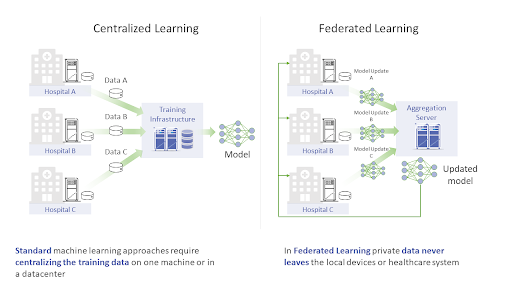
Zobacz na poniższy rysunek. W tradycyjnym podejściu dane zazwyczaj są zbierane i agregowane w różnych lokalizacjach, a jednostka centralna trenuje model przy użyciu wszystkich zebranych danych, czyli wymaga, aby te dane jej wcześniej dostarczyć. Ponieważ trzeba je jakoś do niej przesłać, to takie rozwiązanie zdecydowanie powinno zapalić nam czerwoną lampkę, ponieważ wrażliwe dane medyczne podczas procesu przesyłania nie są bezpieczne. Ale podejście cross-silo FL przychodzi na ratunek! Prywatność jest zachowana, dobra robota!
 |
|
Źródło: https://openfl.readthedocs.io/en/latest/overview.html |
Wyraźnie widać, że podejścia cross-device FL i cross-silo FL definiują skalowalność rozwiązania uczenia federacyjnego (FL). W ciągu ostatnich kilku lat opracowano i opublikowano wiele nowych pomysłów i obecnie przyjmuje się, że istnieje sześć czynników, które są potrzebne do rozróżnienia poszczególnych rozwiązań. Przedstawiono je na poniższym rysunku.
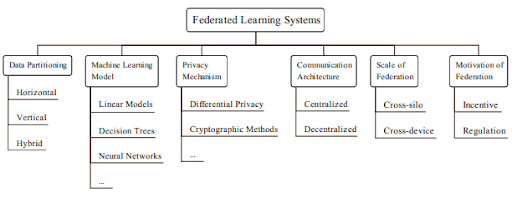 |
Podział danych (Data partitioning) dotyczy sposobu traktowania uczestników procesu współtworzenia modelu oraz ich wybranych cech (rekordów danych) w różnych modelach lokalnych. Podczas gdy pierwotny pomysł zakładał, że każdy węzeł kliencki ma taką samą reprezentację uczestników, istnieją scenariusze oparte na bardziej rzeczywistych uwarunkowaniach, w których dane są partycjonowane przez zestawy cech, a nie przez identyfikator użytkownika. Na przykład bank i firma ubezpieczeniowa mogą mieć dostęp do różnych danych na temat tego samego użytkownika, a mimo to mogą wzajemnie ulepszać swoje modele.
Zastosowany model uczenia maszynowego (Machine Learning Model). Chodzi tu o podstawowy model jaki został zastosowany w uczeniu federacyjnym (FL). Im bardziej złożony jest model, tym bardziej potrzebna jest ciągła wymiana uaktualnień tego modelu. W odniesieniu do uczenia federacyjnego (FL), najważniejszym pytaniem jest, jak agregować lokalne aktualizacje pamiętając cały czas o niezawodności komunikacji i jej przepustowości.
Mechanizm prywatności (Privacy Mechanism) jest kluczowym elementem frameworków uczenia federacyjnego (FL). Podstawową ideą jest unikanie wycieku informacji pomiędzy klientami. Zróżnicowana prywatność (czyli oddzielenie informacji specyficznych dla użytkownika od ogólnie istotnych) oraz kryptografia to dwa często stosowane podejścia, ale jest to dziedzina stale rozwijająca się.
Architektura komunikacyjna (Communication Architecture). Oryginalny pomysł sugerował precyzyjnie zaplanowane podejście do procesu trenowania modelu, gdzie centralny serwer przechowuje zagregowany model, który jest następnie kopiowany w lokalnych jednostkach. Nowsze rozwiązania rezygnują z centralizacji i proponują różne zdecentralizowane mechanizmy aktualizacji. W tych rozwiązaniach węzły klienckie komunikują się z kilkoma innymi równorzędnymi jednostkami i istnieje określona polityka propagacji aktualizacji modelu.
Mówiliśmy już o skalowaniu (Scale of Federation), kiedy wspomnieliśmy mechanizmy cross-device FL i cross-silo FL. Ostatni punkt (Motivation of Federation) dotyczy czynników motywujących do stosowania rozwiązań FL. W niektórych przypadkach to rygorystyczne przepisy zmuszają nas do zastosowania FL. Weźmy na przykład pod uwagę regulację GDPR w Europie, CCPA w USA czy PIPL w Chinach. W innych przypadkach to np. koszty czy zwiększona niezawodność mogą być głównymi siłami motywującymi.
Jeśli zastanawiasz się, dlaczego mamy tak wiele czynników do sprawdzenia, pomyśl o całkowicie różnych wyzwaniach w handlu elektronicznym (spersonalizowane reklamy), finansach (wykrywanie oszustw) lub opiece zdrowotnej (zdalna diagnostyka, itp.). Różne wymagania wymagają różnych rozwiązań. (https://www.nature.com/articles/s41746-020-00323-1).
Jakie są więc główne wyzwania, którym mogą sprostać rozwiązania oparte na uczeniu federacyjnym (FL)?
Skuteczność komunikacji
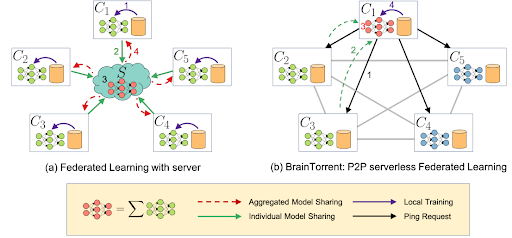
Aktualizacja dużych modeli wymaga wysyłania informacji o dużej objętości. Innym problemem jest ograniczona przepustowość (bandwidth): gdy duża liczba klientów próbuje wysłać dane w tym samym czasie, wielu z nich się to nie uda. Rozwiązanie pierwszego problemu polega na zastosowaniu pewnej formy kompresji, natomiast drugi można rozwiązać poprzez wprowadzenie sieci zdecentralizowanych (peer2peer, gossip), w których aktualizacje są wymieniane lokalnie. Jedno z przykładowych rozwiązań zostało przedstawione na rysunku poniżej.
 |
Prywatność i ochrona danych
Podczas gdy surowe dane źródłowe pozostają tam, gdzie zostały wygenerowane, aktualizacje modelu mogą zostać zaatakowane i ujawnione mogą zostać prywatne informacje. Niektóre rozwiązania są zbudowane wokół tzw. prywatności różnicowej, gdzie tylko statystyczne, ogólne dane są wyliczane i wykorzystywane do szkolenia modelu (https://privacytools.seas.harvard.edu/differential-privacy). Innym ciekawym pomysłem jest wykonywanie obliczeń tylko na zaszyfrowanych danych (tzw. szyfrowanie homomorficzne dla tych, którzy lubią naukowe terminy). Jeszcze inny pomysł idzie w przeciwnym kierunku: rozłóżmy wrażliwe dane na wielu właścicieli danych, ale obliczenia mogą być wykonywane tylko we współpracy. Ciekawe, prawda? https://privacytools.seas.harvard.edu/differential-privacy).
Another interesting idea is to perform computation on encrypted data only (“homomorphic encryption” for those who like scientific terms).
Yet another idea goes to the opposite direction: let us spread the sensitive data across many data owners, but computations can only be done in a collaborative fashion.
Cool, isn’t it?
Różnorodność sprzętu
W przypadku naprawdę dużych systemów uczenia federacyjnego (FL) węzły są najprawdopodobniej dość zróżnicowane pod względem: pojemności pamięci masowej, mocy obliczeniowej i przepustowości komunikacji. Często tylko część z nich uczestniczy w aktualizacji modelu w danym czasie, co skutkuje tym, że trenowanie modelu jest obciążone (biased). Rozwiązanie? Może być nim asynchroniczna komunikacja, próbkowanie aktywnych urządzeń i zwiększona odporność na błędy.
Dane złej jakości
Klienci mogą otrzymać różne dane pod względem jakości (zaszumione, brakujące informacje, itp.) i właściwości statystycznych (różnice rozkładów). Jest to duży problem, który nie jest łatwy do naprawienia, a często nawet do wykrycia. Co gorsza, niektóre węzły wraz z ich lokalnymi modelami mogą zostać skompromitowane, aby umożliwić atak typu „model poisoning” ( (https://proceedings.mlr.press/v108/bagdasaryan20a.html) Dostarczenie specjalnie spreparowanych danych, które są wykorzystane do lokalnych aktualizacji modeli powoduje stopniowe „przeciąganie” zagregowanego modelu w kierunku niepożądanego stanu, powodując jego błędne działanie i narażają na szkody wynikające z błędnych predykcji. To tak jakby uczyć kogoś podając mu fałszywe informacje o świecie.
Jeśli doczytałeś nasze wprowadzenie do tej ciekawej tematyki aż do tego miejsca, to prawdopodobnie podzielasz nasz entuzjazm dla uczenia federacyjnego (FL). Jeśli jesteś gotów „pobrudzić sobie ręce” i samodzielnie przetestować te rozwiązania, oto kilka frameworków FL o otwartym kodzie źródłowym, którymi możesz się pobawić:
- FATE (https://github.com/FederatedAI/FATE) supported by the Linux Foundation.
- Substra: https://docs.substra.org/en/stable/
- PySyft + PyGrid: https://blog.openmined.org/tag/pysyft/
- Nvidia’s Clara: https://developer.nvidia.com/industries/healthcare
- IBM’s solution: https://ibmfl.mybluemix.net/
- OpenFL by Intel: https://openfl.readthedocs.io/en/latest/index.html
- and the very user friendly Flower: https://flower.dev/
Jeżeli masz jakieś pytania, interesujące pomysły lub po prostu chciałbyś porozmawiać na temat uczenia federacyjnego, napisz do nas!