



All you need is AI, AGI, XAI!
At ISRV plc we are on the lookout for powerful IT tools to always meet the highest expectations. That is why we are deeply engaged with AI (Artificial Intelligence). We actively use and improve AI based solutions in various fields spanning from security solutions to traffic (in particular, airport runways ), analysis of behavioral patterns or the improvement of industrial processes.
AI is definitely the magic word of our age so it is only natural that it is the central topic of our first blog!
There are tons of AI related news and amazing success stories, yet there is still much confusion about the very meaning of the terms used throughout. Also, it is alarming that failures are usually not reported openly nor it is clear how success is measured.
In turn, we do not talk about the everyday miracles. Instead, we focus on how to bridge the gap between business and technology. While we do believe that AI is going to stay with us, we also believe in the importance of clear communication with our clients and critical approach to technology.
The momentum of AI is is clearly mirrored by the sheer amount of money spent on funding AI-based startups:
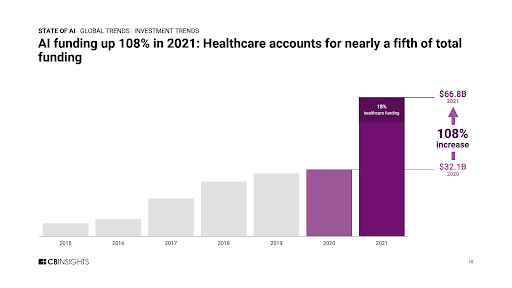 |
| Source: https://www.cbinsights.com/research/report/ai-trends-2021/ |
Is it just a prelude for the next dot-com bubble, or is there indeed potential in this new technology?
The very existence of our applied AI department shows our commitment to the thinking and methodology behind the umbrella term AI. This blog highlights one factor that make us think that AI will stay with us for a long time.
First, let us clarify the confusion surrounding terms like AI and Machine Learning.
What makes a system ‘AI’? For such a popular term, it is quite surprising that there is no scientific consensus about its meaning. To be able to define this term, we need to define what makes a natural system intelligent. To answer this seemingly simple question is the holy grail of a great many scientists of cognitive philosophy, computer science, robotics, and developmental sciences. Instead of deep diving into this exciting question, I’d rather focus on some aspects of intelligence that fill us with awe when we think about our own mental faculties.
By remembering the past, we can recognize and solve challenges similar to what we have seen before. By decomposing big problems into smaller puzzles we learn how to make plans and strategies that will be useful for future problems.
The combination of remembering, learning, and prediction is the foundation of generalization skills, something that machines are still lacking. So no worries, the era of artificial general intelligence (AGI) hasn’t yet arrived.
We believe, in most cases, the term ‘AI’ is misused as it refers to this non-existing AGI. Instead, AI should only be used for systems designed for solving one particular problem (“narrow AI”). In this sense, AI solutions may be seen as imitations of one of our cognitive processes, like scene or text understanding.
In practice, most AI solutions can be seen as a question-answering game: for a given input (image, text, time series) assign a good label (annotation, related info, prediction of the next incoming data, etc). Questions and answers may follow a pattern and when enough such question-answer pairs are presented, the AI system can learn to recognize the pattern. The power of AI is the ability to find and learn these patterns without human interaction or predefined models or concepts. The learned patterns then guide the system to guess the missing parts when just one piece of the pattern (the question) is presented.
Learning is a key concept of intelligence and so nature equipped us with several means. Imitation learning, instruction-based learning, example learning, or curiosity-driven learning are all needed to help survival.
Computer systems extract that hidden information about the question-answer relationship via one of these learning mechanisms, but there is no general theory about mixing these processes.
I think this is one of the reasons why most scientists talk about machine learning and avoid the use of AI.
While it is true that real artificial intelligence has yet to come, the general concepts and the mature tool sets of machine learning are extremely powerful. At Polaris and ISRV we apply similar ideas for quite different tasks, like object detection on traditional RGB or thermal images or instance segmentation on 3D point clouds.
There are a large number of different machine learning models that vary in the applied learning mechanisms and the way the problems are presented to the computer. In general, increased complexity yields increased accuracy (higher likelihood of providing the right answer). But there is no free lunch: the models cannot be used to give insight into the interrelationships found in the data, nor we can see how the model got to the conclusion. In other words, explainability got lost somewhere. The next figure shows the connection between the model’s average performance (accuracy) vs explainability.
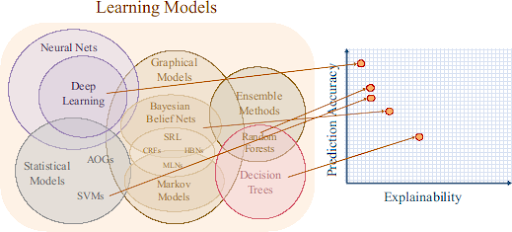
Source: https://www.darpa.mil/program/explainable-artificial-intelligence
You can ask why is it important to understand the internal workings of these complex machines if the end results are so good.
Some say, it is not important, but there is an increased interest in the academy and in the industry as many believe that treating AI solutions like a back box is actually dangerous and can lead to disasters. According to a 2019 PwC study [8], most CEOs interviewed believe that AIs must be explainable to be trusted.
If we cannot explain what is going on, how do we know if we can trust the system in the future? How do we know if it fails or when it fails? What can we gain from the learned patterns?
Explainable AI (XAI) is all about these issues. As the use of AI becomes more pronounced, there are more and more areas where trustworthiness and accountability are of central concern. The source of the image above is DARPA (Defence Advanced Research Projects Agency), the organization responsible for US military research. No surprise that they are among the first large organizations dealing seriously with XAI: they know a bit about the risk of using opaque tools in decision making. Military operations are not the only field where decision-making can gain a lot by using proper AI. Critical infrastructures like spaceships or traffic control will all depend on AI one day. But there are other fields where we already witness smaller or larger hiccups caused by the blind use of AI: healthcare (think of personalized medicine), law, and insurance, to name a few.
In addition, explainability is tied to privacy (GDPR’s ‘right to explanation’), so it becomes mandatory to use interpretable AI solutions [5].
XAI is a set of tools that can be used to show how the given machine learning models make decisions. The aim is to provide insights into how models work, so human experts are able to understand the logic that goes into making a decision.
Due to the diversity of applied AI regarding domains, data types, methods, and scope, there is no ‘One fits all’ XAI solution. But thanks to the increased awareness of the stakeholders across organizations, there are dozens of new methods that help transform oblique AI methods into XAI that is (more) transparent, confident, trustworthy, and interpretable. The following figure shows the number of published reports on XAI in the last couple of years:
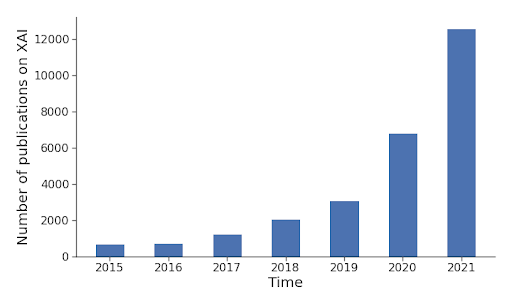 |
| Source of data: shorturl.at/knAR9 |
A recent review of XAI papers [7] published in high-ranked journals showed the following summary about the application of various XAI methods:
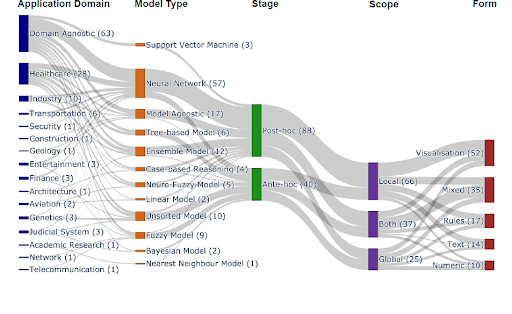 |
| Source: https://arxiv.org/abs/2107.07045 |
As we see, there are many domain-specific solutions, but a large number of methods can be applied generally. The distribution of the underlying machine learning methods follows current trends, and neural networks (deep learning) solutions take the lead. Traditionally it is a bit easier to provide a posthoc analysis and to peek into the mechanism of the applied models. Nevertheless, new ideas help create new solutions that are inherently explainable. The scope of explainability is about analyzing the response to a single input or analyzing average behavior. Finally, an explanation should be human-centric: the way how it is presented matters. So methods are characterized by yielding results in the form of visualizations, rules, text, or numbers.
Here are some examples for local methods, where model output to a given instance can be interpreted. There are global and mixed methods as well, and most methods can also be applied to other modalities like text, audio, or multimodal signals.
A model agnostic method, called LIME -Local Interpretable Model-Agnostic Explanations- [9] creates a surrogate linear model that learns a relationship between the source model’s prediction and the features of the original input. For images, features can be pixels or pixel groups, for tabular data, features are the distinct columns. This method gained popularity as it can be applied on top of many different models and methods.
In multi-class classification problems, models are often used to provide top-N potential labels for a given input. The next example analyzes the top 3 labels yielded by a neural network trained on a large image dataset:
 |
|
The top three predicted classes are “tree frog,” “pool table,” and “balloon.” Sources: Marco Tulio Ribeiro, Pixabay (frog, billiards, hot air balloon). |
For tabular or structured data, where columns represent attributes or well-defined features, feature importance and simple feature interactions can be estimated and visualized using, for example, the SHAP method -”SHapley Additive exPlanations”- [10].
Kaggle uses a FIFA dataset that contains data about several matches. Several tutorials are about analyzing the importance of the individual features when predicting if a given team will have the ‘man of the match’ badge. There are attributes like Opponent Team, Ball possession %, Goals scored, etc.
The following example shows the contribution of each feature to the overall prediction of a model:
 |
| Source: https://www.kaggle.com/code/dansbecker/shap-values/tutorial |
Red features increase, blue features decrease the predicted output from the averaged model output. When calculating feature importance, interactions between features are also accounted for.
 While these are toy examples, explainability is of critical importance in our work of line. For example, we work on a multi-purpose remote sensing autonomous device that can be used to detect surface anomalies or foreign objects. To make it robust, multiple sensors are integrated. Think about detecting loose parts in a highly automized factory plant or debris on the airport runways. The challenge is that we cannot define beforehand what we should find as anomaly is just a deviation from expectations. In turn, the system may miss something important or raises false alert. For security and insurance purposes, we log the events so we can troubleshoot the system or explain the findings. Our solutions is thus transparent and trustworthy by design.
While these are toy examples, explainability is of critical importance in our work of line. For example, we work on a multi-purpose remote sensing autonomous device that can be used to detect surface anomalies or foreign objects. To make it robust, multiple sensors are integrated. Think about detecting loose parts in a highly automized factory plant or debris on the airport runways. The challenge is that we cannot define beforehand what we should find as anomaly is just a deviation from expectations. In turn, the system may miss something important or raises false alert. For security and insurance purposes, we log the events so we can troubleshoot the system or explain the findings. Our solutions is thus transparent and trustworthy by design.
We believe this summary can help build trust by spreading the word that transparent AI is the way to go and when used properly, AI-based tools can help create innovative and efficient solutions to old and new problems as well.
We hope we can help your business grow with our AI experience and passion!
In the following posts we present the areas and projects where we are actively engaged in research and development.
References:
[2] Gunning, D., Vorm, E., Wang, J.Y. and Turek, M. (2021), DARPA’s explainable AI (XAI) program: A retrospective. Applied AI Letters, 2: e61. https://doi.org/10.1002/ail2.61
[3] http://www-sop.inria.fr/members/Freddy.Lecue/presentation/aaai_2021_xai_tutorial.pdf
[4] https://proceedings.neurips.cc//paper/2020/file/2c29d89cc56cdb191c60db2f0bae796b-Paper.pdf
[5] Recital 71 eu gdpr. https://www.privacy-regulation.eu/en/r71.htm, 2018. Online; accessed 27-May-2020.
[6] https://proceedings.neurips.cc//paper/2020/file/2c29d89cc56cdb191c60db2f0bae796b-Paper.pdf
[7] Gohel, Prashant et al. “Explainable AI: current status and future directions.” ArXiv abs/2107.07045 (2021).
[8] https://www.computerweekly.com/news/252462403/Bosses-want-to-see-explainable-AI
[9] Ribeiro MT, Singh S, Guestrin C (2016) “Why should I trust you?” Explaining the predictions of any classifier. In: Proceedings of the 22nd ACM SIGKDD international conference on knowledge discovery and data mining, pp 1135–1144
[10] Scott M. Lundberg and Su-In Lee. 2017. A unified approach to interpreting model predictions. In Proceedings of the 31st International Conference on Neural Information Processing Systems (NIPS’17). Curran Associates Inc., Red Hook, NY, USA, 4768–4777.