



Sztuczna inteligencja wspomagająca zarządzanie zasobami naturalnymi: monitorowanie zieleni miejskiej
W dzisiejszych czasach trudno jest natrafić na informację z dziedziny informatyki (IT), która nie wspominałaby o technologiach związanych ze sztuczną inteligencją (AI). Ponieważ technologie informacyjne (IT) stały się centralną częścią całej naszej gospodarki to sztuczna inteligencja, rozumiana jako część IT, podlegać będzie podobnym procesom. Znajduje ona coraz więcej zastosowań w gospodarce i będzie niebawem wykorzystywana wszędzie tam, gdzie mamy do czynienia z generowaniem danych cyfrowych. To znaczy, że praktycznie wszędzie. Każdy proces biznesowy – czy będzie to produkcja, marketing, zarządzanie zasobami ludzkimi (HR), finanse czy logistyka – jest transformowany przez sztuczną inteligencję. Skąd jednak wiemy, czy sztuczna inteligencja nie jest tylko koleją modą, hasłem medialnym, które niedługo zniknie lub zostanie zastąpione inną modą? Czy to nowe podejście do procesów biznesowych, podejście oparte na intensywnym wykorzystaniu danych cyfrowych stanie się trwałym elementem IT? Obecnie sztuczna inteligencja nie jest już tylko domeną projektów realizowanych w laboratoriach uniwersyteckich. Technologia AI staje się coraz bardziej dojrzała, a nowe odkrycia wprowadzane są na rynek IT w niespotykanym dotąd tempie. Dzięki właściwemu wykorzystaniu technologii AI złożone systemy będą bardziej przejrzyste i ‘wyjaśnialne’, czyli będziemy wiedzieć, dlaczego system podejmuje takie a nie inne decyzje. Dzięki temu sterowanie procesami lub przynajmniej prognozowanie ich przebiegu, będzie coraz łatwiejsze i obarczone mniejszymi błędami.
Aby tak się stało, potrzebujemy nowych perspektyw, nowych modeli organizacyjnych i nowych rozwiązań w sferze IT.
Pomimo tego, że wiele zastosowań sztucznej inteligencji nowej generacji jest naprawdę niesamowitych, to w większości przypadków rola sztucznej inteligencji w systemach informatycznych jest zazwyczaj słabo zrozumiała lub trudna do wyjaśnienia.
Dzięki temu, że rozumiemy logikę biznesową, możemy pomóc zidentyfikować, i przeanalizować procesy oraz tworzyć optymalne rozwiązania dla naszych partnerów biznesowych za pomocą jasnych i przejrzystych metod. Cała „magia” rozwiązania problemu ukryta jest bowiem w ludzkiej kreatywności, a nie w „czarnych skrzynkach” wykorzystujących metody sztucznej inteligencji w jakiś tajemniczy sposób ukryty przed użytkownikiem. Na tym blogu z przyjemnością zaprezentujemy Państwu jeden konkretny przykład, w którym pokażemy, że sztuczna inteligencja może mieć znaczący wpływ na jakość życia całej populacji.
Zadanie: Zarządzanie zielenią miejską w Singapurze
 |
| Źródło: https://cutt.ly/vkW439J |
Singapur – nazywany także Miastem Ogrodem („Garden City”) [1] – zdobył odznakę najbardziej zielonego miasta na Ziemi sadząc od około jednego do dwóch milionów drzew. Jednak utrzymanie tak złożonego systemu, na który składają się parki, lasy i ulice wymaga ogromnej ilości siły roboczej, zasobów oraz umiejętności. Zmiana klimatu sprawia, że to zadanie staje się jeszcze trudniejsze, ponieważ lokalne warunki pogodowe w ciągu ostatnich kilku lat znacznie się zmieniły, skracając żywotność drzew i pomagając w rozprzestrzenianiu się różnych chorób (grzyby, bakterie, owady). Ponieważ jakość życia mieszkańców w dużej mierze zależy od stanu roślinności w mieście, dlatego należy podjąć odpowiednie działania w celu zachowania i poprawy stanu terenów zielonych.
Co w takim razie jest potrzebne, aby zapewnić prawidłowe działanie tego systemu? Rada Parków Narodowych w Singapurze (National Parks Board, NParks), która jest odpowiedzialna za wszystkie publiczne tereny zielone w Singapurze – opracowała plan działani (https://cutt.ly/zkKamWm ).
First, an automated monitoring system was developed that not only helps to assess the present state of the environment, but also it is the foundation of environmental modeling that is used to direct future plantations and support risk analysis (like identifying trees that will likely fall).
As a second step they need a computer aided system that can automate some parts of the data analysis so man power can better be utilized.
Finally they will need a system that can create and fine tune weather and environmental models that can take into account all kinds of data to be collected in the future regarding the physical conditions of the city.
Po pierwsze, opracowano zautomatyzowany system monitorowania, który nie tylko pomaga ocenić obecny stan środowiska, ale także stanowi podstawę modelowania środowiskowego, które służy do kierowania przyszłymi plantacjami i wspomaga przeprowadzanie analizy ryzyka (np. identyfikacji drzew, które prawdopodobnie niedługo padną). Drugim elementem systemu, którego potrzebują do realizacji planów, jest wspomagany komputerowo system, który może zautomatyzować niektóre procesy analizy danych, po to, aby lepiej wykorzystać siłę roboczą.
Ostatnim  elementem będzie system, który będzie w stanie tworzyć i dostrajać modele pogodowe i środowiskowe, uwzględniające wszelkiego rodzaju dane, które będą zbierane w przyszłości, a będą odnosić się do fizycznych warunków miasta. Już sama automatyzacja w procesie zbierania danych stanowi ogromny krok, gdyż jeden ekspert może zbadać tylko kilkadziesiąt drzew dziennie podczas prac terenowych. Obecnie gromadzenie danych odbywa się z wykorzystaniem specjalnych samochodów wyposażonych w systemy czujników LIDAR (ang. Light Detection And Ranging). Samochody te przemierzają miasto i zbierają wysokiej rozdzielczości dane dostarczane z czujników LIDAR oraz dodatkowo zdjęcia panoramiczne, na których rejestrowane jest otoczenie samochodu.
elementem będzie system, który będzie w stanie tworzyć i dostrajać modele pogodowe i środowiskowe, uwzględniające wszelkiego rodzaju dane, które będą zbierane w przyszłości, a będą odnosić się do fizycznych warunków miasta. Już sama automatyzacja w procesie zbierania danych stanowi ogromny krok, gdyż jeden ekspert może zbadać tylko kilkadziesiąt drzew dziennie podczas prac terenowych. Obecnie gromadzenie danych odbywa się z wykorzystaniem specjalnych samochodów wyposażonych w systemy czujników LIDAR (ang. Light Detection And Ranging). Samochody te przemierzają miasto i zbierają wysokiej rozdzielczości dane dostarczane z czujników LIDAR oraz dodatkowo zdjęcia panoramiczne, na których rejestrowane jest otoczenie samochodu.
Źródło: https://cutt.ly/0kW4OMU
{kind=link}
Uzyskane na podstawie czujników obrazy tego samego obiektu, wykonane pod różnymi kątami, mogą być użyte do identyfikacji odpowiadających im obiektów i przypisania im ustalonej pozycji w trójwymiarowym układzie współrzędnych. Odpowiadająca im chmura punktów LIDAR 3D może być następnie wykorzystana do zrekonstruowania szczegółowej morfologii 3D zidentyfikowanego obiektu, w tym przypadku, drzewa: jego wysokości, średnicy i kąta nachylenia pnia drzewa, położenia rozwidlenia pierwszej gałęzi, objętości korony itd.
 |
| W idealnym przypadku chmurę punktów 3D uzyskaną za pomocą pomiarów z czujników LIDAR można podzielić na pewne znaczące części odpowiadające elementom drzewa: takie jak korona, gałęzie i pień drzewa. Precyzyjne, drobnoziarniste modelowanie tych części może pomóc w oszacowaniu całej morfologii drzewa. Źródło: https://cutt.ly/AkW4VeT https://cutt.ly/AkW4VeT |
{kind=link}
Przy pierwszym podejściu do problemu podjęto próbę tradycyjnego, ręcznego zrekonstruowania drzew na podstawie uzyskanych punktów danych w 3D. Użyto przy tym metod, których do dziś używają inspektorzy drzew podczas oceny stanu drzew. To podejście okazało się jednak niezwykle powolne i nieprecyzyjne.
Jednak, gdy wyobrazimy sobie ogromne ilości danych zebranych do analizy, to już samo myślenie o tym może przyprawić nas o zawrót głowy. Dlatego przetwarzanie tych danych również musi być zautomatyzowane. I tu pojawia się wyzwanie! Jak możemy przekształcić specjalistyczną wiedzę ekspertów na taką postać, z której może skorzystać komputer? Niska wiarygodność wspomnianego powyżej tradycyjnego podejścia wynika z faktu, że zostało ono zbudowane na zbiorze skomplikowanych i sztywnych reguł. Naszym głównym zadaniem było więc wymyślenie takiego rozwiązania, które poradzi sobie z bardzo złożonymi przykładami i będzie w stanie zlokalizować drzewa oraz dostarczyć geometryczny model każdego drzewa, z którego można wydajnie (to znaczy szybko i precyzyjnie) uzyskać wszystkie wymagane parametry.
Rozwiązanie. Teoria
Obecnie praktycznie wszędzie możemy zaobserwować zastosowania procesu modelowania jak i użycia modeli 3D. Stosuje się je w różnych dziedzinach, od utrzymania infrastruktury po opiekę zdrowotną (dzisiejsza inżynieria zasadniczo polega głównie na modelowaniu 3D). Lekarze mogą w codziennej pracy np. podczas diagnozowania czy przeprowadzania operacji korzystać z modeli 3D utworzonych na podstawie zebranych wcześniej danych obrazowych. Innym przykładem są autonomiczne pojazdy. Podczas ruchu system takiego pojazdu musi szybko rozpoznać wszystkie istotne obiekty zarówno statyczne jak i poruszające się. Obrazy płaskie, 2D często są jednak trudne do interpretacji lub są zbyt zaszumione, aby były pomocne (słaba widoczność, różnego rodzaju zakłócenia itp. często obniżają ich jakość). Oprócz tego, że same sensory mają swoje fizyczne ograniczenia, to dodatkowo ogromna różnorodność obiektów jeszcze bardziej utrudnia w takim przypadku zadanie. Dlatego rozwiązania oparte na regułach (tzw. systemy regułowe) po prostu zawodzą.
Tutaj na ratunek przychodzi sztuczna inteligencja. Właściwie powinniśmy mówić w tym przypadku o tzw. uczeniu maszynowym (ang. Machine Learning). Uczenie maszynowe (w skrócie ML) to pojęcie węższe niż AI, jest to termin określający różne metody obliczeniowe, będące często podstawą systemów AI, a które całkiem dobrze sprawdzają się w rzeczywistych sytuacjach spotykanych w codziennym życiu.
Kluczowym aspektem tych różnych metod uczenia maszynowego jest to, że mogą one odkrywać pewne wzorce w dostarczanych im danych i następnie uczyć się wzorców i relacji między danymi (czyli obserwacjami) a ich opisem dostarczanym przez ekspertów danej dziedziny. Te opisy danych są to tzw. tagi, nazywane też adnotacjami lub etykietami. Proces uczenia polega na stopniowym dostrajaniu parametrów algorytmu, tak aby coraz lepiej (to znaczy popełniając coraz mniej błędów) przypisywać tagi (czyli adnotacje) do danych. W naszym przypadku danymi są punkty 3D, natomiast tagi (adnotacje) to etykiety typu „pień drzewa” lub „korona drzewa”, itd. Przypisując odpowiedni tag do każdego pojedynczego punktu, w rzeczywistości dokonujemy segmentacji semantycznej: punkty są dzielone na specyficzne grupy lub klastry. W przypadku gdy muszą zostać wykryte i oddzielone podobne obiekty (np. dwa różne drzewa), wtedy używana jest dodatkowa etykieta jako tzw. identyfikator (ID): punkty oznaczone tym samym ID należą do tego samego obiektu. To zadanie jest zwykle nazywane segmentacją instancji.
Rozwiązanie w praktyce
Dane, dane, dane
Do uczenia modelu potrzebne są przede wszystkim dane. Jeżeli chodzi o bazy danych zawierających chmury punktów 3D wraz z adnotacjami to dostępnych jest sporo takich baz. Większość z nich ma jednak różnego rodzaju wady, które czynią je bezużytecznymi dla naszego projektu. Niektóre nie zawierają informacji o drzewach, ich rozdzielczość jest zbyt niska lub zastosowane kategorie po prostu nie są wystarczająco dobre. Jako przykład można podać proste etykiety typu: „roślinność wysoka” czy „roślinność niska”, które są używane w danych dostępnych pod tym adresem: https://www.semantic3d.net/.
Z tego powodu naszym pierwszym krokiem było to, aby pomóc naszym partnerom w tworzeniu dużego i heterogenicznego zestawu danych treningowych na podstawie ich własnych pomiarów. Ponieważ podczas zbierania danych używanych jest kilka rodzajów sensorów (LIDAR, zdęcia), dlatego zestaw danych zawiera zarówno chmury punktów 3D jak i odpowiadające im obrazy 2D. Jednak chmury punktów 3D nie są ustrukturyzowane (w przeciwieństwie do obrazów 2D, w których każdy punkt danych jest powiązany z siatką). Rozdzielczość jest wysoka, dane są zaszumione, a obiekty 3D bardzo złożone (drzewa zazwyczaj nie mają prostych, regularnych kształtów). Idealny zbiór danych treningowych składałby się z kilku tysięcy dobrze opisanych chmur punktów 3D (tzn. punktów z adnotacjami) (nazwijmy je „woluminami 3D”) oraz dodatkowo z obrazów 2D z adnotacjami (tzn. obrazów podzielonych na segmenty). W rzeczywistości jednak możemy korzystać tylko z tego co mamy dostępne. Dlatego wszystkie przedstawione poniżej wyniki uzyskano korzystając z zaledwie kilkuset chmur punktów 3D (czyli kilkuset „woluminów 3D”)!
Wybór modelu i szkolenie
W czasie, gdy zaczynaliśmy pracę nad tym projektem, dostępnych było tylko kilka wydajnych modeli, które potrafiły wywnioskować jaka jest morfologia obiektów 3D na podstawie nieustrukturyzowanych chmur punktów 3D.  Wykluczyliśmy niektóre z nich, ponieważ wymagały zbyt dużej ilości danych lub wydawały się zbyt wolne, aby mogły być zastosowane w praktyce. Była to ważna lekcja. Chociaż istnieje znacznie więcej obrazów 2D, a do tego algorytmy segmentacji 2D są dość dobrze rozwinięte, to analiza modeli 3D jest w rzeczywistości szybsza, ponieważ w tym przypadku dane 3D są to tzw. dane rzadkie. Dlatego zamiast stosować skomplikowane podejście, w którym bezpośrednio, od razu integrować dane 2D i 3D, zbudowaliśmy i dostroiliśmy dwa oddzielne modele: do segmentacji 2D i 3D. Ostateczne rozwiązanie obejmowało dwa kroki. Najpierw wytrenowaliśmy model, aby zlokalizować drzewa (tzn. środek pni drzew na ziemi). Następnie przeszkoliliśmy masz połączony model dwóch wcześniej opublikowanych rozwiązań w celu segmentacji poszczególnych drzew oraz ich części.
Wykluczyliśmy niektóre z nich, ponieważ wymagały zbyt dużej ilości danych lub wydawały się zbyt wolne, aby mogły być zastosowane w praktyce. Była to ważna lekcja. Chociaż istnieje znacznie więcej obrazów 2D, a do tego algorytmy segmentacji 2D są dość dobrze rozwinięte, to analiza modeli 3D jest w rzeczywistości szybsza, ponieważ w tym przypadku dane 3D są to tzw. dane rzadkie. Dlatego zamiast stosować skomplikowane podejście, w którym bezpośrednio, od razu integrować dane 2D i 3D, zbudowaliśmy i dostroiliśmy dwa oddzielne modele: do segmentacji 2D i 3D. Ostateczne rozwiązanie obejmowało dwa kroki. Najpierw wytrenowaliśmy model, aby zlokalizować drzewa (tzn. środek pni drzew na ziemi). Następnie przeszkoliliśmy masz połączony model dwóch wcześniej opublikowanych rozwiązań w celu segmentacji poszczególnych drzew oraz ich części.
Oto przykład rezultatu uzyskanego wg naszego rozwiązania, dla do danych przykładowego drzewa:
  |
| Segmentacja semantyczna 3D. Po lewej stronie widzimy oryginalny widok przechwycony jako obraz 2D. Po prawej widać, że model oddziela słupy elektryczne od korony i dużych gałęzi drzewa. Kolory (czyli tzw. „maska”) pochodzą z segmentowanych danych 3D, dzięki czemu współrzędne każdego punktu można odwzorować na reprezentacji 2D. |
Ocena
Wydajność wytrenowanych modeli została zmierzona jako dokładność na tej części zestawu danych z adnotacjami, która nigdy nie była używana podczas procesu uczenia. Proces ten naśladuje sposób, w jaki model będzie działał na przyszłych danych, co czyni ocenę bardziej obiektywną. Przewidywane przez model etykiety porównano z adnotacjami ekspertów. Dokładność (ang. mean Intersection Over Union, mIoU) wykrywania drzewa i segmentacja części drzewa była następująca:
| MIOU | Tło | Korona | Pień-gałęzie |
| 2D | 97% | 90% | 70% |
| 3D | 99% | 96% | 78% |
.
.
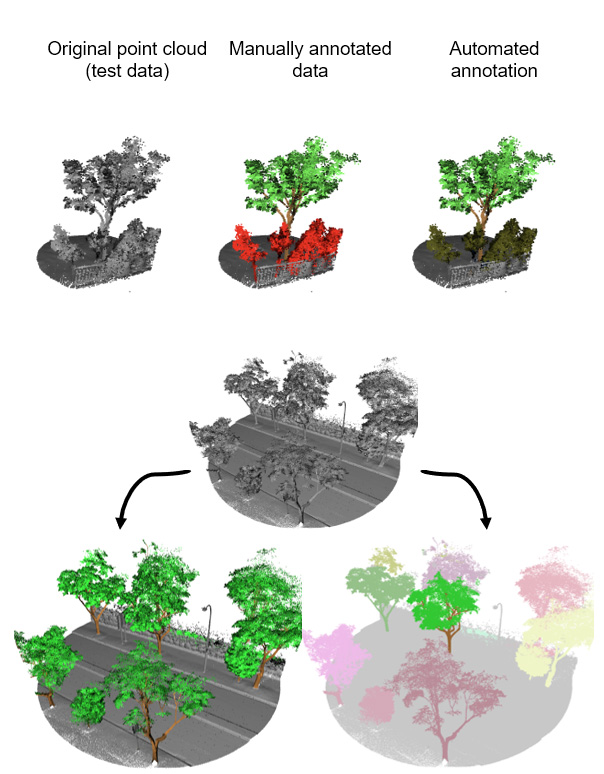 |
| Wytrenowane modele są w stanie segmentować zarówno części drzewa (A) jak i poszczególne drzewa (B) |
Od rozwiązania do wersji produkcyjnej
Podczas współpracy z partnerem nasz główny wkład polegał przede wszystkim na stworzeniu rdzenia rozwiązania ML. Na tym jednak praca się nie skończyła. Doradzaliśmy naszemu partnerowi jak dobrać najlepszą infrastrukturę programową i sprzętową oraz zapewniliśmy dalsze wsparcie w integracji naszego rozwiązania z istniejącym środowiskiem analitycznym posiadanym przez NParks.
Końcowe rozwiązanie zostało utworzone i wdrożone w prywatnej chmurze. Wstępne przetwarzanie przychodzących danych sensorycznych, wnioskowanie w oparciu o utworzony model oraz rejestrowanie i przechowywanie wyników jest odbywa się w wydajny, rozproszony sposób, w którym każdy krok może być wizualizowany i w razie potrzeby ręcznie korygowany. Modele można dalej ulepszać, wykorzystując to, czego uczymy się z tych trudniejszych przypadków, w których potrzebna jest korekta dokonana przez człowieka. W tym celu istnieje dedykowany system pętli zwrotnej, który zbiera oznaczone przypadki i inicjuje nowy proces uczenia się.
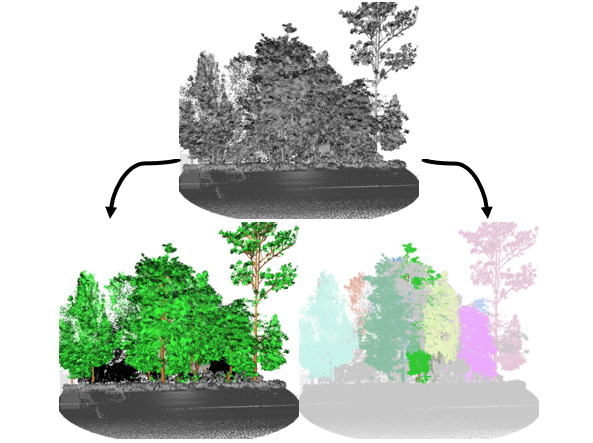 |
| Model działa nawet dla mocno przeładowanych grup drzew, aczkolwiek z mniejszą dokładnością. Potwierdza się znana prawda, że rozwiązanie ML jest tak samo dobre, jak dobry jest zestaw szkoleniowy. W tym konkretnym przypadku adnotacja okazała się bardzo trudna nawet dla ludzkich ekspertów dokonujących adnotowania danych. |
Jak możemy pomóc?
W trakcie realizacji projektu zetknęliśmy się z wieloma wyzwaniami typowymi także dla innych zadań praktycznych: „przetłumaczenie” zadania na język algorytmów, analiza i doskonalenie już istniejących rozwiązań, tworzenie odpowiednich danych do szkolenia itd. Mamy nadzieję, że ten blog dał Państwu przydatne i jednocześnie interesujące spojrzenie na świat sztucznej inteligencji i jej zastosowań w biznesie i przemyśle.
Jeśli masz złożony problem, który Twoim zdaniem mógłby zostać rozwiązany przez nasz zespół AI, porozmawiajmy! [1] “Garden city” Vision Is Introduced [11 May 1967] https://eresources.nlb.gov.sg/history/events/a7fac49f-9c96-4030-8709-ce160c58d15c